2020
有所得
有所失
2020
有所得
有所失
面试完全没有提到跟简历有关的内容,基本就是问智力题,感觉答得非常一般。
最终面试结果为未通过。
就是一个博弈论的问题,应该算Best Response逐层上推就好了,当时面试只讲了思路,没有算出来。
将其转变成一个三维的单位球,问求表面能够取多少向量,两两之间夹角的余弦值小于0.7。可以通过用正三角形的构造方法,来利用立体角构造上界。但并不知道怎么计算准确值,当时面试官说可以计算出准确的结果。
本质是利用直角边为和的直角三角形。
首先通过取得到,然后依次采用,,取倒数,平方,就可以得到。开方之后再次通过以上流程就可以得到,依次类推可以得到任意整数。
对于任意有理数,实际上要可以得到任意的,由上面的流程,我们可以在知道的情况下,得到,同时可以得到任意的。
那么对于任意的,总是用大的减去小的,就可以最终化成一个的形式,这个是可以得到的,之后再反复利用倒数和的操作反推回去,就可以得到任意有理数了。
CQ资产的笔试题目,笔试时间为40分钟,题量为9道。总体感觉笔试难度适中,时间有一点紧。由于笔试题目本身为英文,这里不做额外的翻译,解答为笔者所做,可能存在错误。
个人笔试结果为通过。
Given the following function definition: (4 min, score = 3)
1 | Define f(x): |
How many additions will take place while evaluating f(f(f(3)))?
Solution:
Total additions:.
A stock’s price fluctuates every day by going up exactly 5% or going down exactly 5%. Assume that each direction is equally likely. Assume zero trading cost, zero interest rate, and no dividends and splits. What strategy is most likely to be profitable after 100 days?
(3 min, score = 3)
A. Buy or sell will produce same profitable
B. Cannot know / no strategy can be profitable
C. Buy the stock
D. Sell the stock
Solution:
D
Below is a list of asymptotic complexities of 8 functions, each with length N input:
O(N^3)
O(Log(N))
O(Sqrt(N))
O(N * log(N))
O(2^N)
O(N^N)
O(N!)
O(Log(Log(N)))
Please sort the functions by order of growth, with slower growing functions first. (your answer shall be a sequence of letters, for example “BACDFHGE”)
(4 min, score = 3)
Solution:
HBDCAEGF
Solution:
Half is , half is .
Solution:
If is even, , then , so it’s a perfect square.
If is odd, , then , it’s a perfect square if and only if is a perfect square.
We have:
So there are 5 odds that meet the condition, .
Totally, integers.
Solution:
So the range of possible values of is .
Solution:
Solution:
It’s easy to know, triangle ABC is a right triangle.
Solution:
Use the stock code to select stocks. If the stock code is a prime number, buy it and hold. The strategy is pretty strange because there should be no useful information in the stock code.
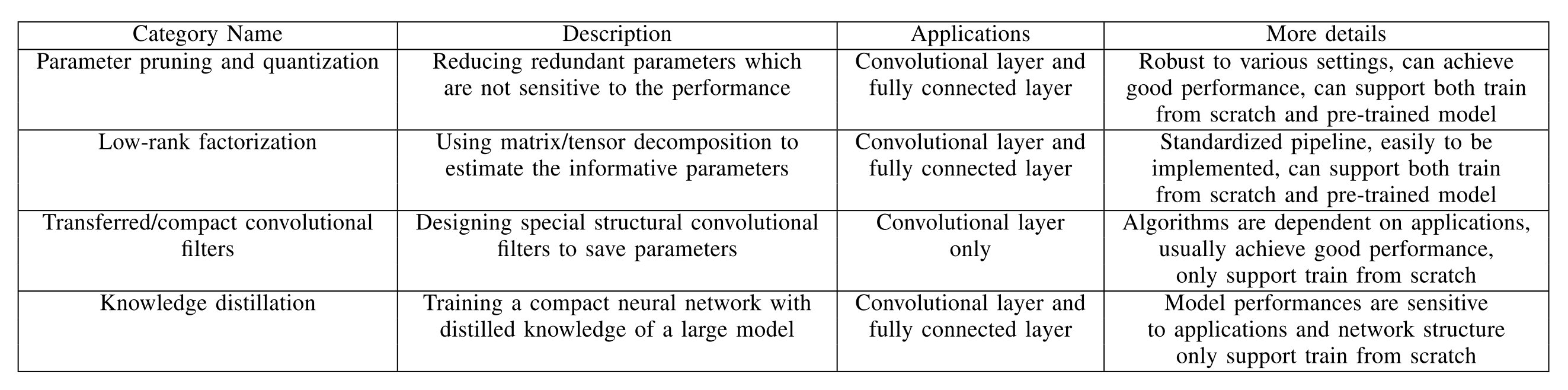
这是一篇模型压缩领域的综述,主要从参数剪枝和量化(Parameter pruning and quantization),低秩分解(Low-rank factorization),转移/紧致卷积滤波器(Transferred/compact convolutional filters)和知识蒸馏(Knowledge distillation)四个方面来对于已有的模型压缩方法进行综述。这篇文章发表的时间点为2017年,可能对于较新的成果涉及并不是那么广泛,但是对于模型压缩加速领域的一个初步了解而言感觉还是可以的。
四个方向的总体概览如下所示:
网络量化是通过用来表示权重的bits数目来将原网络进行压缩的,比如可以采用16-bit浮点或者是8-bit整数来表示权重,极限情况下可以采用1-bit的二进制权重神经网络。
同时也有一种方法是通过权重共享来实现模型的压缩,可以认为是通过Hash方法将所有近似的权重对应于一个Hash值,即使得相同的权重只被存放一次。这里通过哈夫曼编码来减少存放索引所需要的空间,从而可以通过索引去读取对应的内容。
流程如下所示:
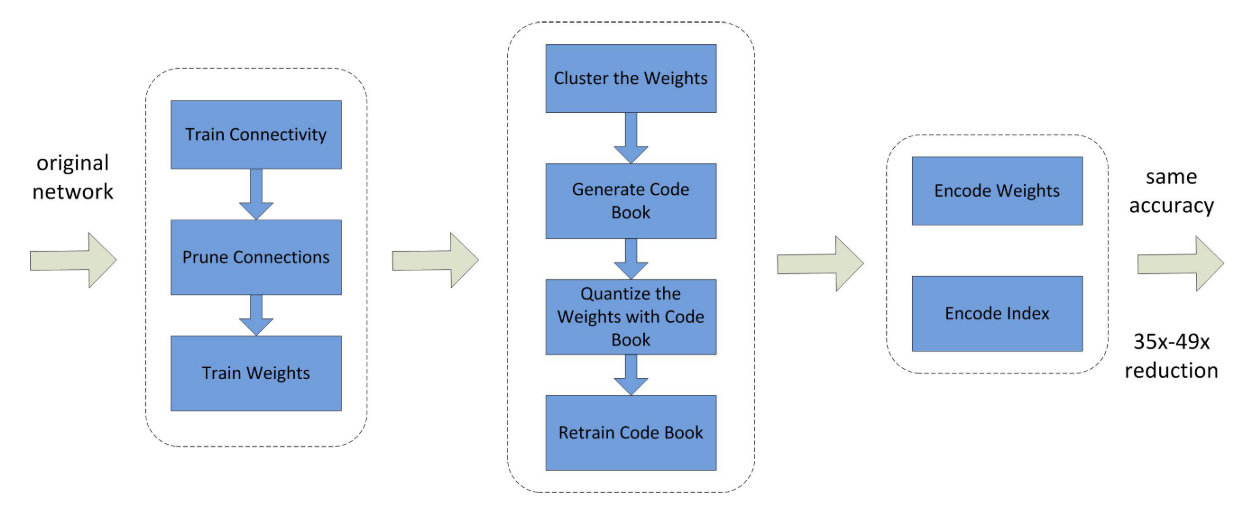
他实际上在利用Code Book量化之后会对共享的权重进行重训,来得到更好的效果。最后得到的就是权重的Code Book,每个权重存放的是对应的索引而不是权值。
(好奇.jpg,离散值的梯度反传等等怎么搞?找到了个知乎链接,有空看看,估摸着是不一定会看了)
缺点:
网络剪枝和共享已经被用于减少网络复杂性和处理过拟合任务。一个早些的剪枝方法是有偏的权重衰减。最优脑损害(The Optimal Brain Damage)和最优脑外科医生(the Optimal Brain Surgeon)方法基于损失函数Hessian矩阵来减少连接层的参数,这些工作期望能够比基于大小的剪枝方法(比如权重衰减)有更高的准确率。
网络剪枝的最近一个方向是剪枝掉预训练模型当中的冗余权重,通过data-free的方式来去除掉冗余的神经元和连接。
同时也有一个方向是训练带有稀疏性约束的CNN网络。在最优化问题当中,稀疏性约束通常就是和正则化。
缺点:
结构化矩阵的方式从我的理解来看,实际上就是通过更少的参数来表示全连接层的那个大矩阵,从而降低需要的参数量。由于有的结构化方法可以通过特性进行高效的矩阵-向量乘法,所以不仅可以降低内存的消耗,同时可以加速模型的训练和推断。
(好奇.jpg x 2,卷积实际上应该也是一种结构化矩阵,这玩意能不能在受限情况下进行搜索?)
一种方法就是通过循环投影(circulant projections),通过向量,一个循环矩阵可以如下定义:
这使得内存消耗从变成了,同时循环矩阵也可以利用快速傅立叶变换(FFT)来加速计算过程。提供一个维的向量,通过上述矩阵的计算时间复杂度为。
缺点:
结构化约束会使得模型有偏,损害模型的性能(我的角度来看就是做了不该做的假设)
很难找到合适的结构化矩阵,当前也缺乏理论指导
卷积操作占据了深度CNNs模型中的最大计算篇幅,因此减少卷积层能够提升压缩率同时也能加快运算速度。
对于卷积核,它可以被认为一个4D张量。基于张量分解的想法驱使我们本能的认为4D张量的冗余性去除会有一个显著提升,这是一个特殊的方式去移除冗余性。注意到全连接层,它能够被视为一个2D矩阵并且低秩也能有所帮助。
很长时间以来,人们使用低秩滤波器去加速卷积,例如,高维DCT(discrete cosine transform,)和小波系统(wavelet systems)各自使用张量积去构造从一维DCT和小波。
低秩估计是逐层而做的。一层的参数在低质估计后固定下来,而上面的层是微调基于一个重构误差准则。这些是典型的用于压缩2D卷积滤波器的低秩估计方法。根据这个方向,Canonical Polyadic(CP)分解是一个用于核张量的方法。人们使用非线性的最小二乘去计算CP分解。然而,找到最好的低秩估计在CP分解中式一个病态问题,并且最好的(K是秩的值)估计可能是不存在的。
正如前面所提,全连接层可以看成是2D矩阵,因此上述的方法(指低秩估计的方法)也能够应用到这儿(指全连接层的分解)。也有工作应用截断奇异值分解去分解全连接层用于设计紧凑的多任务深度学习框架。
缺点:
CNNs 是参数有效的对于转换的不变性,对于输入图片表示的不变性,而这对于训练深度模型而不导致过拟合是重要的。尽管目前还缺失强理论证明,但是大量的经验事实支持平移不变性和权重共享对于好的预测性能是重要的。 使用转移卷积滤波器去压缩CNN模型的想法受到研究工作启发,它引入了等价理论。让是一个输入,是一个网络层和是一个转换矩阵。等价性的概念如下所定义:
表明转换了 的输入 然后传递它到层次的网络(即得到后再用网络作用)应该有同样的结果在第一次用网络映射然后再转换表示(即先得到,再用作用)。注意:和不是必须相同的。根据这个理论,应用转换层或者滤波器去压缩整个网络模型是合理的。从经验观察,深度CNNs同样受益于使用大的卷积滤波器通过应用确定的转换到一个小的基础偏置滤波器的集合,由于它扮演了一个模型的正则化。
在这个方向,有许多最近的研究工作去建立一个由基础滤波集合构建的卷积层。(就是从不同的角度定义函数 )
缺点:
知识蒸馏的基本想法就是将深度大模型中蒸馏知识到一个浅层的网络当中。压缩的网络会尝试学习深层复杂网络的这样一个映射。通常的方法就是通过学习softmax之后的分布来讲大模型的知识蒸馏到小模型当中。当然也有一些工作来尝试学习高层隐层当中的表征,或者是feature maps来进行知识蒸馏,以获得相对于最终的分布更多的信息。通常而言大模型和压缩模型的容量结构相差比较大,假设其中间结果有着相似效果是一个过强的约束。
缺点:
数据集主要为主流的图像相关任务数据集,对应的Baseline模型为主流的CV经典模型,如ResNet,VGG nets等。
记为模型,为模型所含有的参数数量,为模型的运行时间,大部分工作是采用的平均每epoch的训练时间,但是实际上测试时间也是可以的。利用的星号上标来表示压缩后模型的对应指标,通常采用的评价指标有以下几种:
压缩比率(compression rate)
索引空间节省量(index space saving)
加速比率(speedup rate)
通常而言压缩比和加速比是高度相关的,因为越小的模型通常跑的越快。事实上在不同的任务当中这可能和不同的层类型是相关的。大多是任务的运算主要集中在全连接层,但是对图像分类任务而言,绝大多数的运算主要集中在卷积层,因为一开始的图像面积比较大,卷积层运算非常耗时间。所以具体的压缩和加速方法需要对应于不同的应用着重关注不同类型的网络层。
基于深度学习的图像检索任务通常是利用CNN网络进行特征提取,将图片转化为一个向量,然后通过之后通过向量来进行相关图片的检索。那么怎么利用CNN提取出一个有效的全局描述符实际上就成为了一个非常关键的步骤。
这篇论文提出了一种不需要训练多个网络再融合就能够将多个全局描述符进行融合的方法。
CGD模型的总体结构如下:
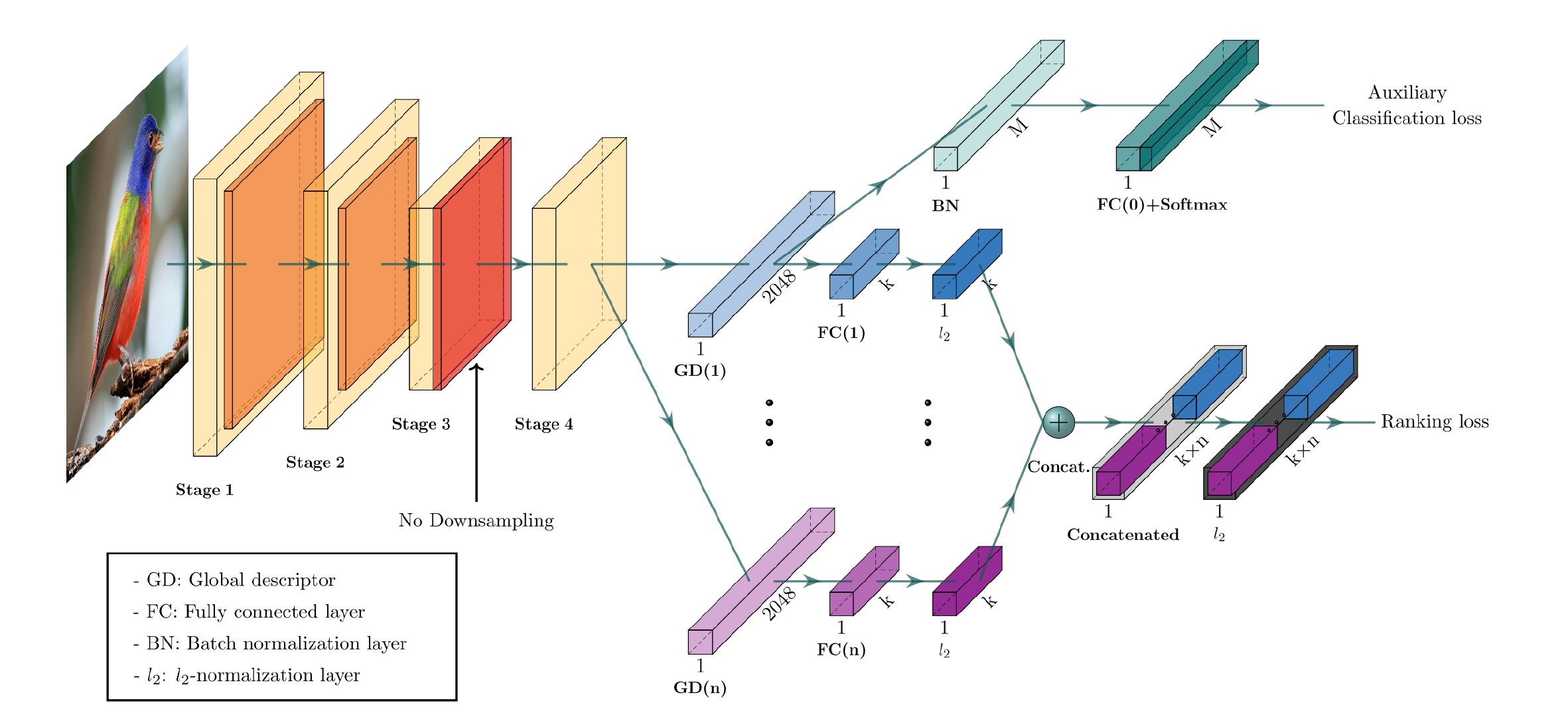
可以看到它主要由一个CNN backbone和两个模块组成。下面的主模块是主要的用于学习图像表示的模块,他组合了多个全局描述符,利用ranking loss进行优化,上方是一个用来对CNN backbone进行fine-tune的辅助模块,利用classification loss进行优化。最终的loss为以上两个loss的总和,这样就可以直接将整个网络进行一个端到端的训练了。
这边是把最后一层卷积层的结果作为输入,是一个的三维张量,记作,通过一个池化操作可以转化为一个向量,池化操作可以写成如下一个统一形式:
其中下标c表示的是c通道的结果,三种全局描述符的表示对应如下:
如总框架中所示的,在经过一个池化操作之后,需要需要通过一个全连接层降维再进行L2正则化,得到最终的输出特征
其中表示第个分支,的三种取值对应上述提到的三种池化操作,最终的特征向量是一个组合描述符,将多个分支的结果进行拼接再进行L2正则化:
这样就在一个CNN backbone的基础上,只通过了很少的参数添加就获得了组合描述符的效果。
辅助模块通过第一个全局描述符来对接前面的CNN backbone进行fine-tune。通过一个分类任务来帮助最大化图片的组间距离,同时使得模型的训练速度更快。这里采用Temperature scaling和label smoothing的方法来帮助训练,最终的softmax loss定义如下:
是用来缩放的温度,越低实际上扩大了不同类之间的差距,增强学习的效果。
CGD完成的实际上是多种描述符的组合,在这里一共有3种池化操作。如果有多个描述符的话,第一个的结果要做用到下游的分类任务,所以相对于其他有所区别。于是这里一共有12种不同的描述符:
选择的方法就是首先用单个描述符来进行测试,跑3次实验,之后选择其中最优的和次优的进行组合。
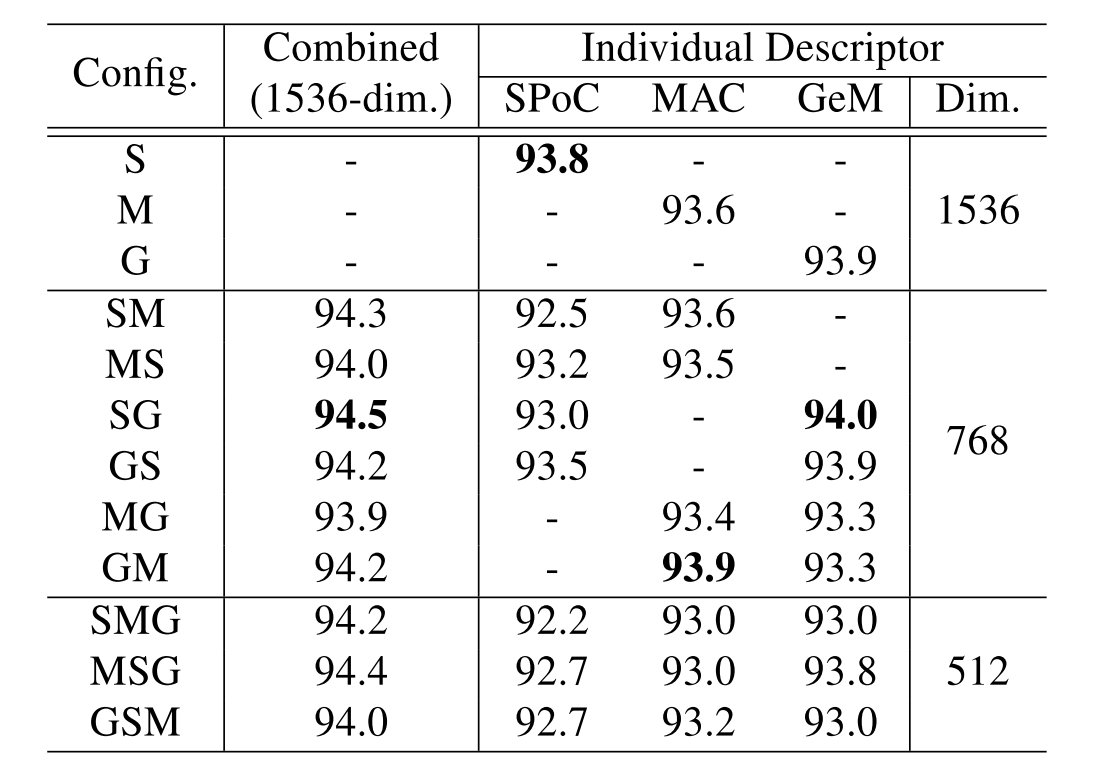
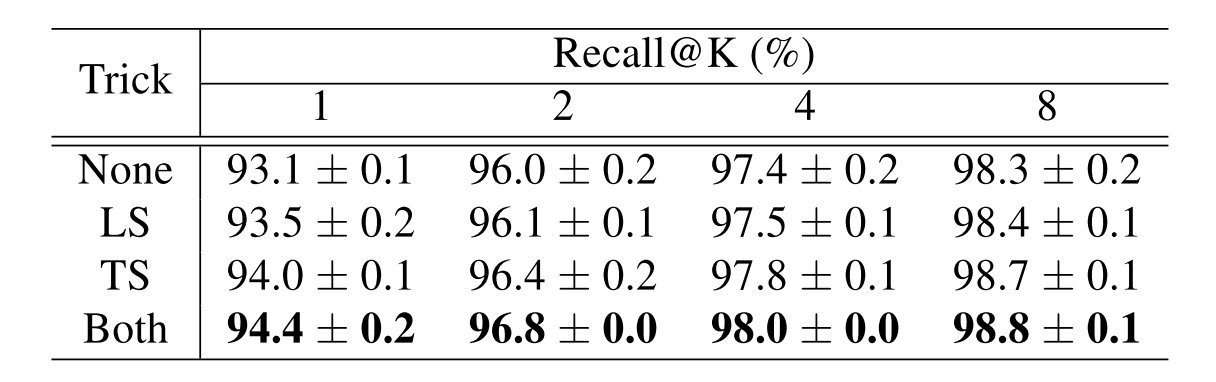
在实验当中得到的结果是,两种trick都采用在ResNet-50 backbone上有着一定程度的提升:
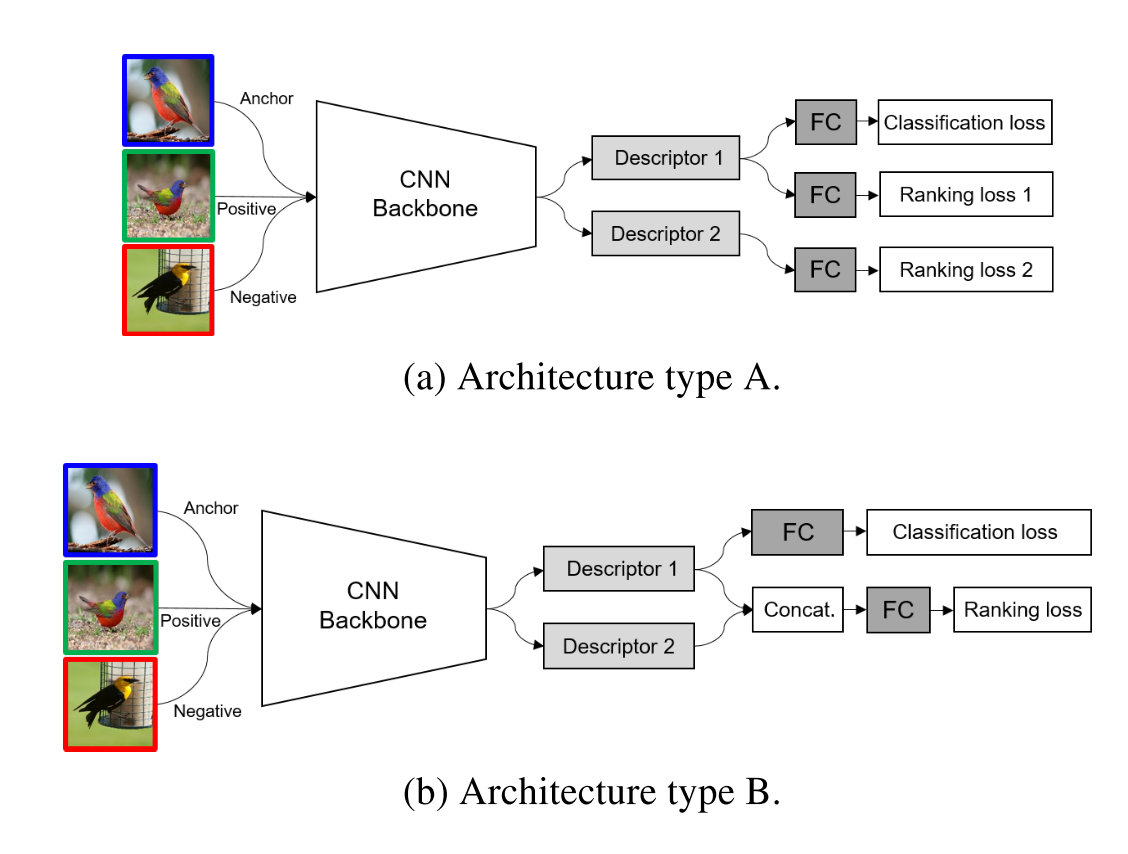
对于在什么位置进行多种全局描述符的融合也进行了试验,两种方法如下所示:
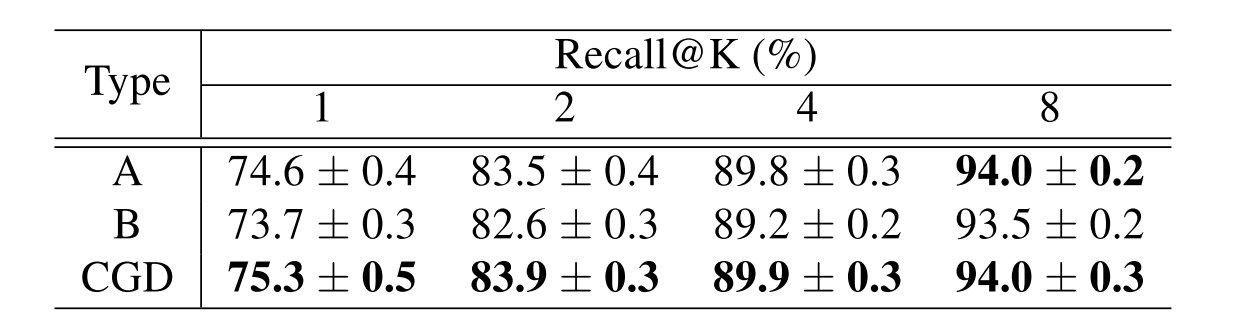
得到的结果如下,可以发现CGD模型的框架在总体情况下是更优的:
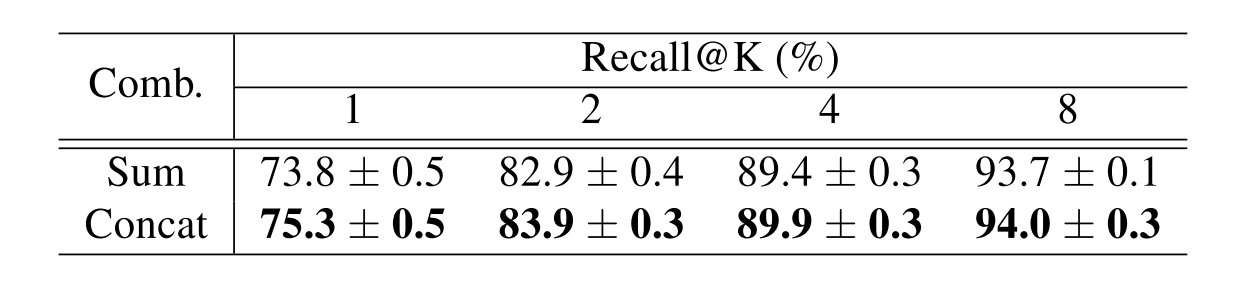
对于组合的方法考虑了直接进行求和和进行拼接两种方法,可以发现拼接可以保存更多的特性和多样性,能够取得更好的最终结果:
实现的具体参数列在下方:
1 | transform: |
提供一个基于PyTorch的实现如下:
1 | import torch |
对于Anaconda的使用往往通过Jupyter Notebook或者是Jupyter Lab来进行的,可以通过以cell为单位交互式的运行,能够极大的提升效率。但是当面对与多个虚拟环境的时候,需要在Jupyter Lab当中进行虚拟环境的配置。
进行虚拟环境的管理需要安装nb_conda包:
1 | conda install nb_conda |
安装完成之后可以在创建notebook时,或者在执行中通过kernel选项来进行虚拟环境的选择。
当创建了新的conda虚拟环境的时候,可以在新环境上面安装ipykernel,之后重启Jupyter Lab即可,安装指令如下:
1 | conda install -n env_name ipykernel |
2020年由于新冠疫情影响,出国人数减少,再加上近年来硕士名额转成博士名额的趋势,使得保硕士难度会比往年更高,当然如果这个趋势不变,可以预见难度只会越来越高。
比较幸运的是今年还是拿到了想要的offer成功上岸,这里将北大叉院和信科保研的相关经历记录,希望能够帮助之后准备保研面试的同学。不过今年由于疫情,很多流程都较往年有所更改,估计参考价值有限。
入学在工学院,大一平转信科,GPA前10%,辅修北大国发院经济学双学位。
大一大二都拿了奖学金和奖励,无国奖,无论文,无企业实习经历。
从个人角度来看,自身并不想走学术这条路,排序为:
大三在AIIC(北京大学人工智能创新中心)有一年实习经历,计划为保AIIC的学硕,同时在比较早就报了叉院项目希望能够保底。
今年由于疫情取消了机考,形式为笔试+面试。
笔试一共有3道题目,题目主要考察基础的编程与算法相关的内容,难度较低。可以参考数据结构或是算法分析的课程内容来进行复习。
面试形式为多对一,多为面试老师,一位学生,流程大致如下:
英文自我介绍,时长大约两分钟
简历相关问题(问了我简历上的一个项目大概是怎么做的)
个人意向相关
数学基础问题(就我与其他人的交流好像其他人没怎么被问到)
当表明自己不想做学术的时候感觉就应该凉了,但是可能是因为数学问题都答得没什么问题,所以最后给了个Waiting List,在七月底补录为优秀营员,我直接拒绝了offer。
推荐准备北大叉院的保研面试还是以学术导向为主,最好能够展现出自己想在学术领域继续研究的意图。
由于疫情影响取消了机考之后,信科只有一轮面试,具体形式内容应当是各个系所自己组织,我报的是北大AIIC的人工智能产业创新学硕项目。
形式同样为多对一,多位面试老师,一位学生。由于之前已经在中心实习一年加上老师对于实习生已经有过了一轮面试,整体的面试氛围偏向轻松。
没有官方邮件通知,第二周周中直接公示名单,成功上岸。
首先要解决的就是为什么需要空间金字塔池化(SPP)这个问题,它到底为了什么而出现。
对于以往的神经网络结构大部分所需要的都是固定的网络大小输入,但是现实中很多图片数据并不是固定大小的输入。以往的方法往往是通过裁剪(Crop)和扭曲(Warp),但是前者会导致信息的丢失,后者可能会导致图片的失真,都会使得数据分布发生一定变化。
SPP解决的就是图片大小不同的问题,使得输入可以是任意宽和高的图片。
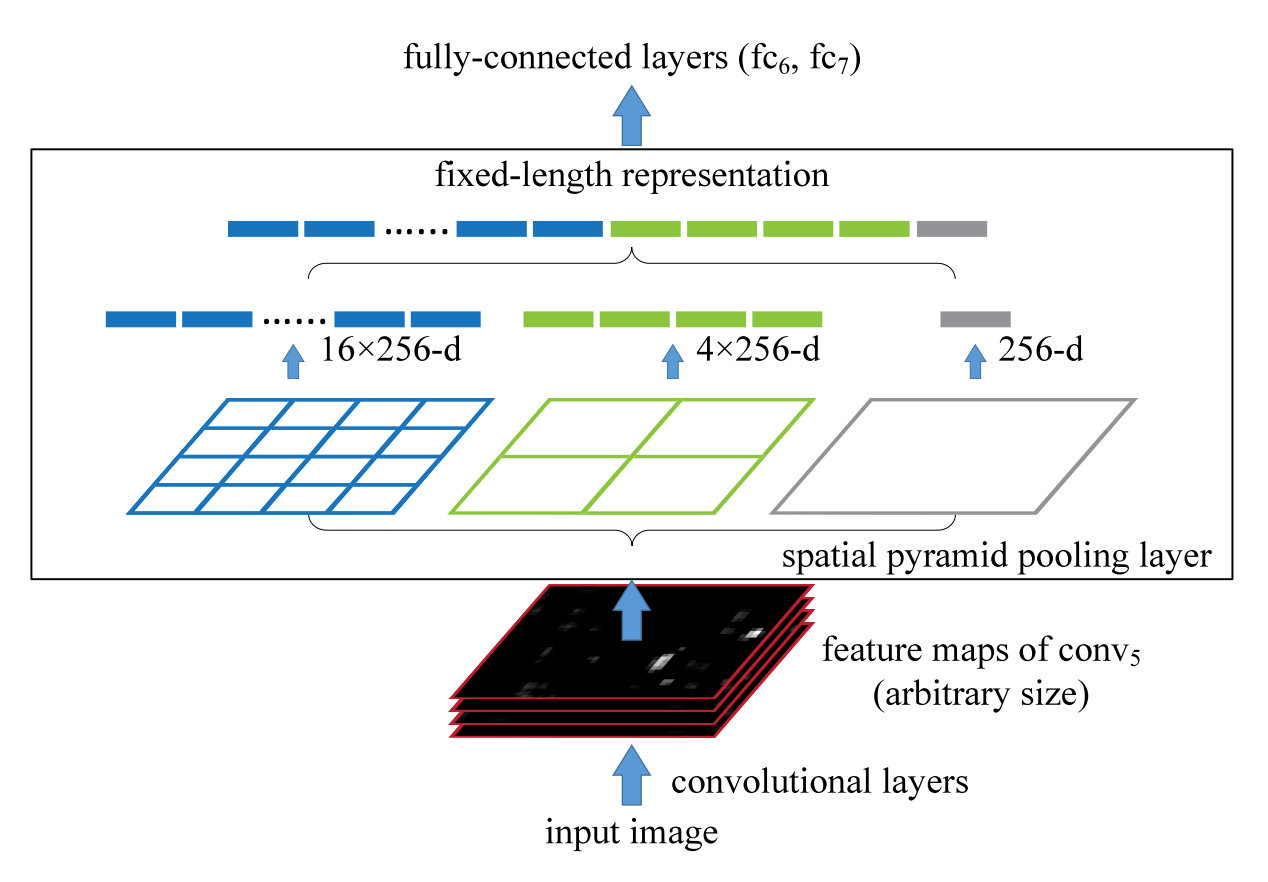
如上图所示的SPP-Net 中有若干个并行的池化层,将卷积层的结果 池化成 的一层层结果,再将其所有结果进行拼接之后与 FC 层相连。
由于只有最后的FC层对于输入的大小是存在硬性要求的,当输入为任意大小的图片时,我们可以随意进行卷积、池化。在过FC 层之前,通过 SPP 层,将图片抽象出固定大小的特征(即多尺度特征下的固定特征向量抽取)。
好处有以下几点:
单输入size大小的训练方法同普通的训练相同,这里所需要的就是设置好对应的pooling层的stride和window size,以便于之后的SPP层可以输出正确的结果。事实上,这里为了探究single-size的训练主要是为了来测试金字塔池化的行为是否符合预期。
为了防止切换数据带来的overhead过高,这里假设有两种size的输入图片,每一种size训练一个epoch之后切换到另一种。事实上发现采用多尺度的图片,收敛速率和单尺度图片是相似的,并没有带来收敛速率上的损失。
以上两种方法都是只针对训练阶段的,在测试阶段,可以直接将任何尺寸的图片输入到SPP-net当中。
基于PyTorch框架的实现如下,在github上看了几个实现大多数都是通过论文当中提供的公式来进行实现的,少部分发现了公式在面对一些不太友好数据的情况会出现输出维度不同的问题,增加了padding的计算方法。
本着不重复造轮子的原则,在我使用的PyTorch-1.5.0当中提供了AdaptiveMaxPool2d和AdaptiveAvgPool2d方法,直接采用其进行构造,代码逻辑会更为清晰和行数也会更短。
同时提供一个outputdim的辅助函数,通过输入的之前卷积层结果的channel数来计算输出维度。
1 | import torch |
测试如下:
1 | spp = SpatialPyramidPooling() |
输出结果为:
1 | torch.Size([8, 448]) |
的确将不同大小的输入给调整成了统一大小。
Arthur owns a ski resort on a mountain. There are landing spots on the mountain numbered from to from the top to the foot of the mountain. The spots are connected with one-directional ski tracks. All tracks go towards the foot of the mountain, so there are no directed cycles formed by the tracks. There are at most two tracks leaving each spot, but many tracks may enter the same spot.
A skier can start skiing from one spot and stop in another spot if there is a sequence of tracks that lead from the starting spot and end in the ending spot. Unfortunately, recently there were many accidents, because the structure of the resort allows a skier to go through dangerous paths, by reaching high speed and endangering himself and the other customers. Here, a path is called dangerous, if it consists of at least two tracks.
Arthur wants to secure his customers by closing some of the spots in a way that there are no dangerous paths in the resort. When a spot is closed, all tracks entering and leaving that spot become unusable.
Formally, after closing some of the spots, there should not be a path that consists of two or more tracks.
Arthur doesn’t want to close too many spots. He will be happy to find any way to close at most spots so that the remaining part is safe. Help him find any suitable way to do so.
Input
The first line contains a single positive integer — the number of test cases. test case description follows.
The first line of each description contains two integers and () — the number of landing spots and tracks respectively.
The following lines describe the tracks. Each of these lines contains two integers and () — indices of the starting and finishing spots for the respective track. It is guaranteed that at most two tracks start at each spot. There may be tracks in which starting and finishing spots both coincide.
It is guaranteed that the sum of over all test cases does not exceed .
Output
For each test case, print a single integer () — the number of spots to be closed. In the next line, print distinct integers — indices of all spots to be closed, in any order.
If there are several answers, you may output any of them. Note that you don’t have to minimize . It can be shown that a suitable answer always exists.
Example
input
1 | 2 |
output
1 | 2 |
Note
In the first sample case, closing any two spots is suitable.
In the second sample case, closing only the spot is also suitable.
给出一个有向无环图,所有定点的出度不超过2,入度不做限制,同时限定边的起始点一定比终止点要小(是从山顶到山脚的滑雪道)。
要求去掉其中的一些顶点(不多于),使得图中没有长度超过2的路径。
贪心想法为从节点1(山顶)向后分层级来遍历,如果是第一条连边则保留,第二条则删除相关联节点。
如之后代码中所表示的level,这里通过level将所有顶点分成三类,下标为节点对应的level,形式化表述如下:
对应的就是删除所有中的顶点,下面来证明为什么可以保证不超过:
由于至少有一条来自的边,而一个顶点最多两条出边,所以最多有条出边,那么有着,同理有着。于是,所以。
只需要从山顶到山脚扫描一遍就可以确定哪些是当中的顶点,这里的时间复杂度为。
注意:如果对整个level数组进行memset操作,有一个的case会超时!
1 |
|
因为就是准备笔试时候自己刷了刷题,所以基本都只在本地跑过了样例
Implementation
1 |
|
Implementation
1 |
|
Binary Search
1 |
|
Search
1 |
|
DP
1 |
|
Implementation
1 |
|
BFS
1 |
|
Binary Indexed Tree
1 |
|
DP
1 |
|
DFS
1 |
|