基于深度学习的图像检索任务通常是利用CNN网络进行特征提取,将图片转化为一个向量,然后通过之后通过向量来进行相关图片的检索。那么怎么利用CNN提取出一个有效的全局描述符实际上就成为了一个非常关键的步骤。
这篇论文提出了一种不需要训练多个网络再融合就能够将多个全局描述符进行融合的方法。
提出了CGD网络(combination of multiple global descriptors),可以融合多种全局描述符并且进行端对端的训练,同时在backbone,loss等方面都有着良好的拓展性。
通过量化实验说明了融合多种全局描述符比单个有着更好的表现。
在多个图像检索数据集上都达到了sota水平。
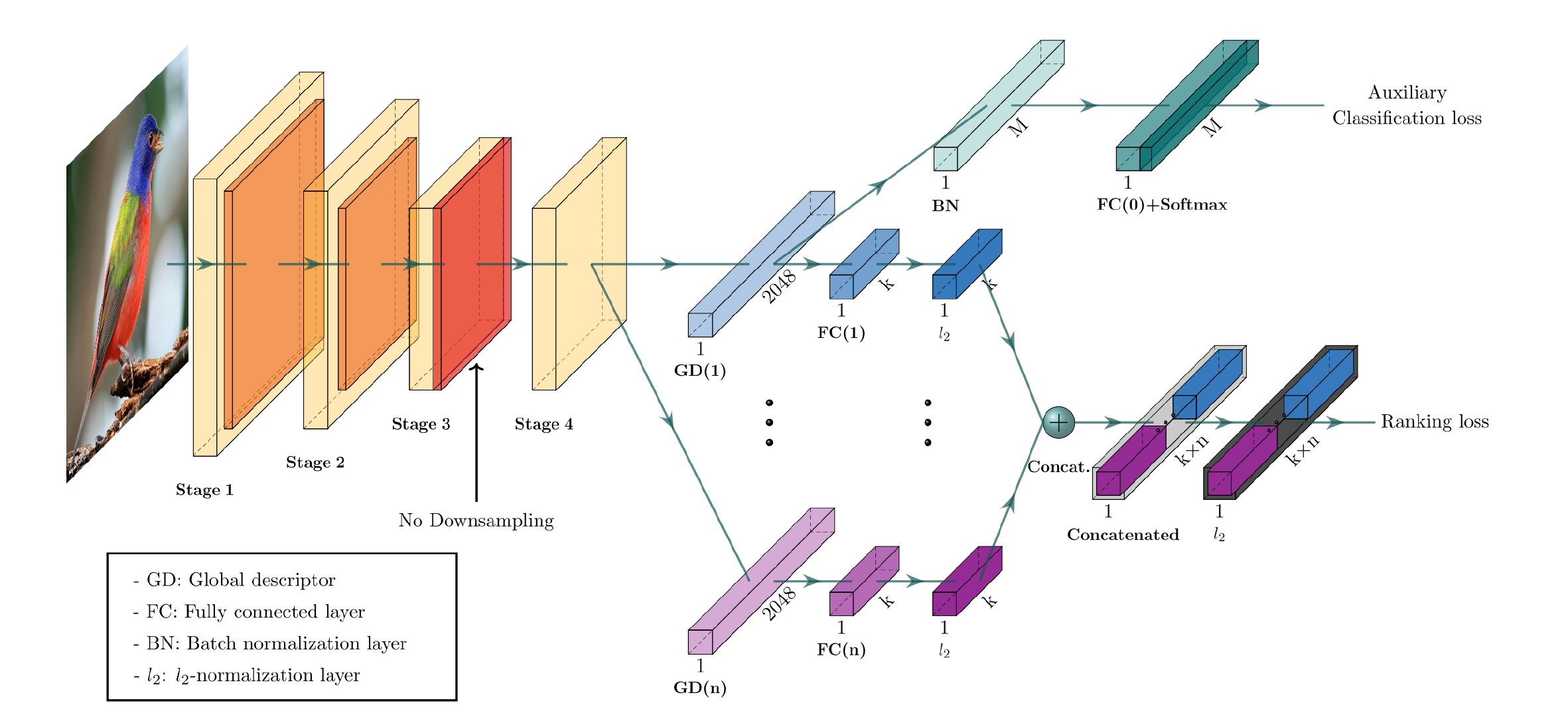
CGD模型的总体结构如下:
可以看到它主要由一个CNN backbone和两个模块组成。下面的主模块是主要的用于学习图像表示的模块,他组合了多个全局描述符,利用ranking loss进行优化,上方是一个用来对CNN backbone进行fine-tune的辅助模块,利用classification loss进行优化。最终的loss为以上两个loss的总和,这样就可以直接将整个网络进行一个端到端的训练了。
这边是把最后一层卷积层的结果作为输入,是一个C × H × W C\times H\times W C × H × W X \mathcal{X} X
f c = ( 1 ∣ X c ∣ ∑ x ∈ X c x p c ) 1 p c f_c = \left(\frac{1}{|\mathcal{X}_c|} \sum_{x \in \mathcal{X}_c}x^{p_c}\right)^{\frac{1}{p_c}}
f c = ( ∣ X c ∣ 1 x ∈ X c ∑ x p c ) p c 1
其中下标c表示的是c通道的结果,三种全局描述符的表示对应如下:
SPoC:p c = 1 p_c=1 p c = 1
MAC:p c → ∞ p_c\rightarrow \infty p c → ∞
GeM:默认为p c = 3 p_c=3 p c = 3
如总框架中所示的,在经过一个池化操作之后,需要需要通过一个全连接层降维再进行L2正则化,得到最终的输出特征Φ ( a i ) \Phi^{(a_i)} Φ ( a i )
Φ ( a i ) = W ( i ) ⋅ f ( a i ) ∣ ∣ W ( i ) ⋅ f ( a i ) ∣ ∣ 2 , a i ∈ { s , m , g } \Phi^{(a_i)} = \frac{W^{(i)}\cdot f^{(a_i)}}{|| W^{(i)}\cdot f^{(a_i)}||_2},\qquad a_i\in \{s,m,g\}
Φ ( a i ) = ∣ ∣ W ( i ) ⋅ f ( a i ) ∣ ∣ 2 W ( i ) ⋅ f ( a i ) , a i ∈ { s , m , g }
其中i i i i i i a i a_i a i
ψ C G D = Φ ( a 1 ) ⊕ … ⊕ Φ ( a i ) ⊕ … ⊕ Φ ( a n ) ∥ Φ ( a 1 ) ⊕ … ⊕ Φ ( a i ) ⊕ … ⊕ Φ ( a n ) ∥ 2 \psi_{C G D}=\frac{\Phi^{\left(a_{1}\right)} \oplus \ldots \oplus \Phi^{\left(a_{i}\right)} \oplus \ldots \oplus \Phi^{\left(a_{n}\right)}}{\left\|\Phi^{\left(a_{1}\right)} \oplus \ldots \oplus \Phi^{\left(a_{i}\right)} \oplus \ldots \oplus \Phi^{\left(a_{n}\right)}\right\|_{2}}
ψ C G D = ∥ ∥ Φ ( a 1 ) ⊕ … ⊕ Φ ( a i ) ⊕ … ⊕ Φ ( a n ) ∥ ∥ 2 Φ ( a 1 ) ⊕ … ⊕ Φ ( a i ) ⊕ … ⊕ Φ ( a n )
这样就在一个CNN backbone的基础上,只通过了很少的参数添加就获得了组合描述符的效果。
辅助模块通过第一个全局描述符来对接前面的CNN backbone进行fine-tune。通过一个分类任务来帮助最大化图片的组间距离,同时使得模型的训练速度更快。这里采用Temperature scaling和label smoothing的方法来帮助训练,最终的softmax loss定义如下:
L S o f t m a x = − 1 N ∑ i = 1 N log exp ( ( W y i T f i + b y i ) / τ ) ∑ j = 1 M exp ( ( W j T f i + b j ) / τ ) L_{Softmax}=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{\exp \left(\left(W_{y_{i}}^{T} f_{i}+b_{y_{i}}\right) / \tau\right)}{\sum_{j=1}^{M} \exp \left(\left(W_{j}^{T} f_{i}+b_{j}\right) / \tau\right)}
L S o f t m a x = − N 1 i = 1 ∑ N log ∑ j = 1 M exp ( ( W j T f i + b j ) / τ ) exp ( ( W y i T f i + b y i ) / τ )
τ \tau τ
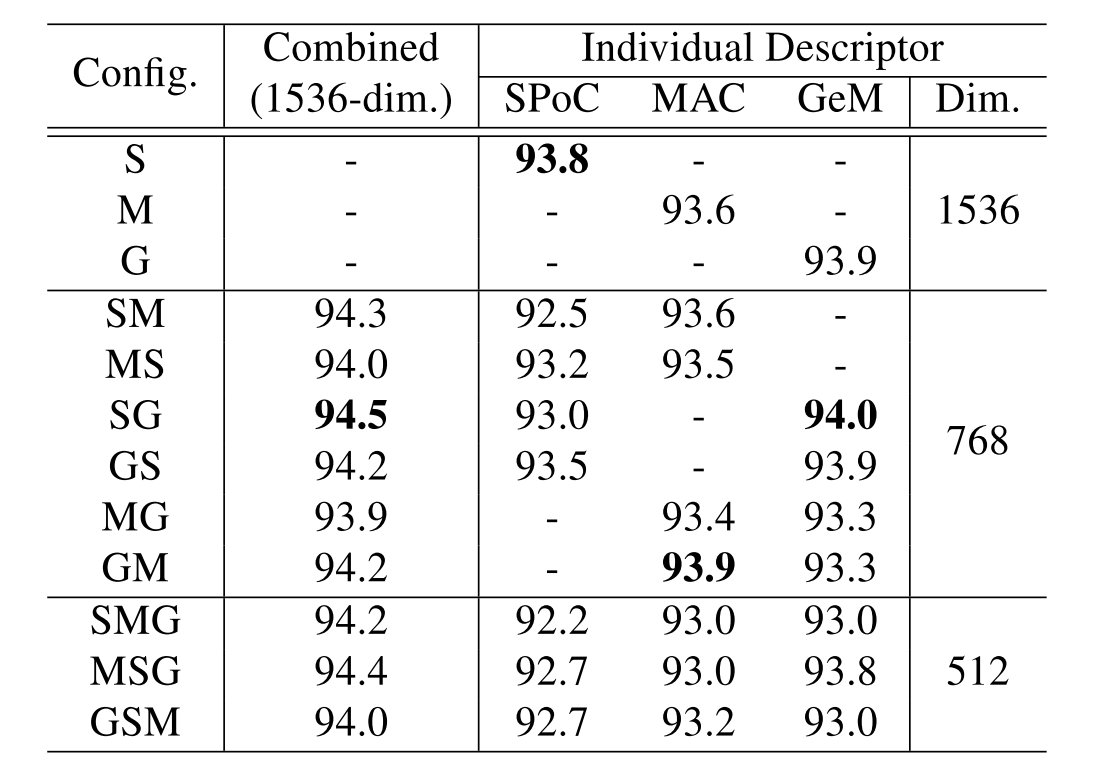
CGD完成的实际上是多种描述符的组合,在这里一共有3种池化操作。如果有多个描述符的话,第一个的结果要做用到下游的分类任务,所以相对于其他有所区别。于是这里一共有12种不同的描述符:
S , M , G , S M , M S , S G , G S , M G , G M , S M G , M S G , G S M S,M,G,SM,MS,SG,GS,MG,GM,SMG,MSG,GSM
S , M , G , S M , M S , S G , G S , M G , G M , S M G , M S G , G S M
选择的方法就是首先用单个描述符来进行测试,跑3次实验,之后选择其中最优的和次优的进行组合。
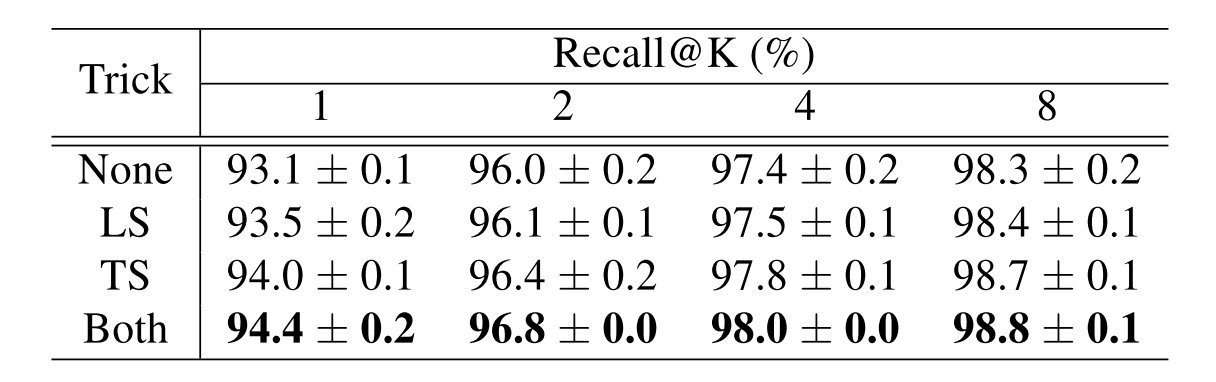
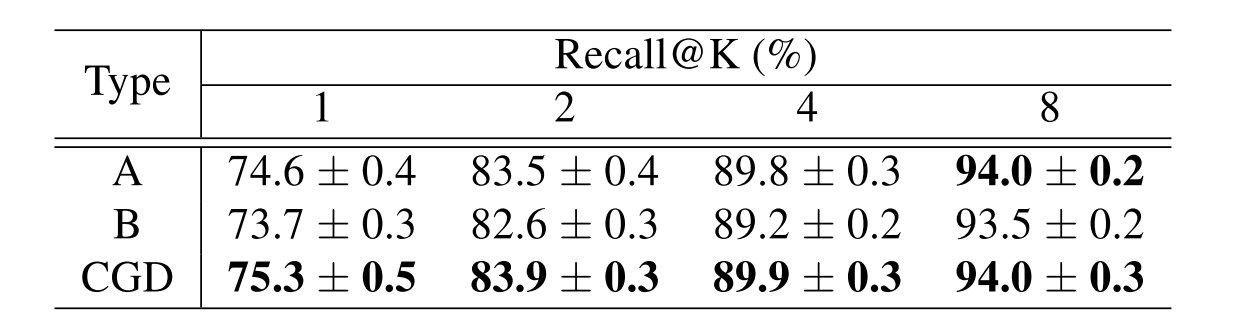
在实验当中得到的结果是,两种trick都采用在ResNet-50 backbone上有着一定程度的提升:
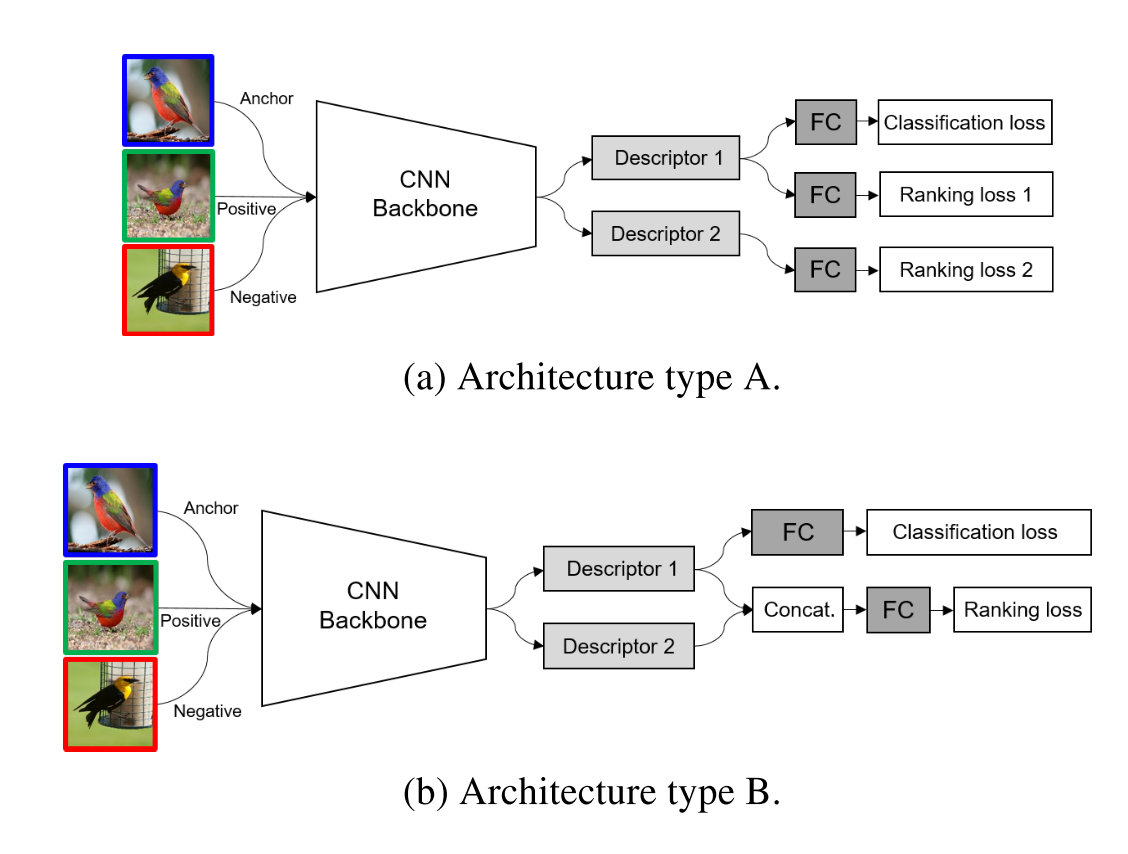
对于在什么位置进行多种全局描述符的融合也进行了试验,两种方法如下所示:
得到的结果如下,可以发现CGD模型的框架在总体情况下是更优的:
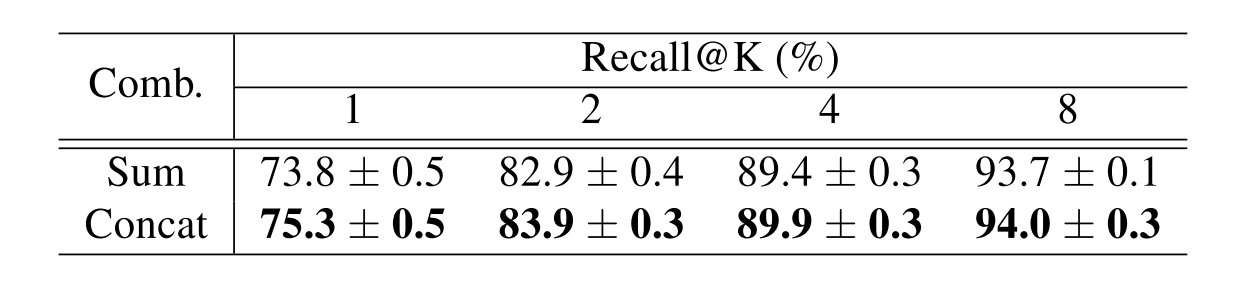
对于组合的方法考虑了直接进行求和和进行拼接两种方法,可以发现拼接可以保存更多的特性和多样性,能够取得更好的最终结果:
实现的具体参数列在下方:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 transform: training phase: resize: 252 x 252 random crop: 224 x 224 randomly flipped to horizontal inference phase: resize: 224 x 224 optimizer: Adam: learning rate: 1e-4 batch size: 128 margin for triplet loss: 0.1 temperature: 0.5 label smoothing: 0.1
提供一个基于PyTorch的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import torchimport torch.nn as nnimport torch.nn.functional as Fclass Identify (nn.Module): def __init__ (self ): super ().__init__() def forward (self, x ): return x class L2Normalization (nn.Module): def __init__ (self, p=2 , dim=-1 ): super ().__init__() self.p = p self.dim = dim def forward (self, x ): out = F.normalize(x, p=2 , dim=-1 ) return out class GlobalDescriptor (nn.Module): def __init__ (self, pooling_type, trainable=False ): super ().__init__() if trainable: self.p = nn.Parameter(torch.tensor([3. ])) else : self.p = 3 if pooling_type == 's' : self.method = nn.AdaptiveAvgPool2d(1 ) elif pooling_type == 'm' : self.method = nn.AdaptiveMaxPool2d(1 ) else : def GeM (x ): mean_value = torch.mean(torch.pow (x, self.p), dim=[-1 , -2 ], keepdim=True ) out = torch.sign(mean_value) * torch.pow (torch.abs (mean_value), 1 / self.p) return out self.method = GeM self.flatten = nn.Flatten() def forward (self, x ): out = self.method(x) out = self.flatten(out) return out class CGDModel (nn.Module): def __init__ (self, gd_config, feature_dim=1536 ): super ().__init__() assert feature_dim % len (gd_config) == 0 self.pretrained_model = torch.hub.load('zhanghang1989/ResNeSt' , 'resnest101' , pretrained=True ) self.pretrained_model.layer4[0 ].avd_layer = Identify() self.pretrained_model.layer4[0 ].downsample[0 ] = Identify() self.backbone = nn.Sequential( self.pretrained_model.conv1, self.pretrained_model.bn1, self.pretrained_model.relu, self.pretrained_model.maxpool, self.pretrained_model.layer1, self.pretrained_model.layer2, self.pretrained_model.layer3, self.pretrained_model.layer4, ) self.n = len (gd_config) self.k = feature_dim // self.n self.gds = nn.ModuleList([GlobalDescriptor(i) for i in gd_config]) self.bn = nn.BatchNorm1d(2048 ) self.fc0 = nn.Linear(2048 , CLASS_NUM) self.fcs = nn.ModuleList([nn.Sequential(nn.Linear(2048 , self.k), L2Normalization()) for i in range (self.n)]) self.l2norm = L2Normalization() def forward (self, x ): shared_feature = self.backbone(x) descriptors = [] for i, (gd, fc) in enumerate (zip (self.gds, self.fcs)): feature = gd(shared_feature) if i == 0 : logit = self.bn(feature) logit = self.fc0(logit) feature = fc(feature) descriptors.append(feature) global_descriptor = torch.cat(descriptors, dim=-1 ) global_descriptor = self.l2norm(global_descriptor) return global_descriptor, logit