梯度提升树
首先考虑梯度提升树,考虑一个有n个样本,每个样本有m个特征的数据集D={(xi,yi)},一个集成树模型实际上得到的使用K个具有可加性质的函数,得到的输出对应如下所示:
y^i=ϕ(xi)=k=1∑Kfk(xi),fk∈F
对于每一棵树而言,一个输入会被映射到一个对应的叶节点,这个节点上的权重就对应这个输入的结果。在这里目标函数使用被正则化的形式:
L(ϕ)=i∑l(y^i,yi)+K∑Ω(fk)
whereΩ(f)=γT+21λ∥w∥2
其中前半部分l代表的是损失函数,用来量化预测值与真实值之间的差距,后者是正则化项,用来控制模型的复杂度,防止过拟合。对于树模型而言,正则化项的第一项控制叶节点的数量,后一项控制每个叶节点的权重。如果去掉正则化项,实际上就是普通的梯度提升树。
在对于第t颗树的时候,我们需要优化的目标函数实际上以下式子:
L(t)=i=1∑nl(yi,y^i(t−1)+ft(xi))+Ω(ft)
将损失函数展开到二阶近似:
L(t)≈i=1∑n[l(yi,y^i(t−1))+gift(xi)+21hift2(xi)]+Ω(ft)
其中y^i(t−1)是前t−1颗树的结果,在当前的优化实际上是一个常数,将其移除之后得到t步的优化函数为:
L~(t)=i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)
定义Ij={j∣q(xi)=j} 为叶节点j上面对应的样本集,于是可以修改求和形式如下:
L~(t)=i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)=j=1∑Ti∈Ij∑[gift(xi)+21hift2(xi)]+γT+21λj=1∑Twj2=j=1∑Ti∈Ij∑[giwj+21hiwj2]+γT+21λj=1∑Twj2=j=1∑T⎣⎡⎝⎛i∈Ij∑gi⎠⎞wj+21⎝⎛i∈Ij∑hi+λ⎠⎞wj2⎦⎤+γT
当对于一个确定的树结构,γT为常量,前面这一项对应于wj的一个二次表达式,可以得到最优解为:
wj⋆=−∑i∈Ijhi+λ∑i∈Ijgi
带入可以知道最优的值为:
L~(t)(q)=−21j=1∑T∑i∈Ijhi+λ(∑i∈Ijgi)2+γT
上式仅仅与树结构q有关,所以可以作为一个树结构的度量,越小说明这个树结构越好。由于没有办法穷举所有可能的树结构,所以只能贪心地对于树结构去改进,增添新的分支。假设我们希望把一个节点分离成两个子集IL和IR那么这个分裂会带来的L~的减少就是:
Lsplit=Lbefore−Lafter=21[∑i∈ILhi+λ(∑i∈ILgi)2+∑i∈IRhi+λ(∑i∈IRgi)2−∑i∈Ihi+λ(∑i∈Igi)2]−γ
这个值即为分裂带来的增益,应当越大越好,其中前面一项是因为分裂所带来的提升,后面一项是对于分裂使得模型复杂度增加的惩罚。所以γ相当于给节点分裂设定了阈值,只有当分裂带来的增益超过这个阈值,才会进行树分裂,起到了剪枝的效果。
节点分裂算法
精确贪心算法
关键问题就是如何找到最优的分裂方案来获得最大的分裂增益,最直观的方法就是进行遍历,只要对于数据所有可能的分裂方式进行一次遍历,就可以从中找到增益最大的分裂方式。为了算法能够执行的更加高效,我们需要在最开始对于数据进行一次排序,这样就只要在有序数据上进行一次遍历就可以了。

近似算法
精确贪心算法由于需要遍历所有的可能,非常消耗时间。并且当数据没有办法全部放进内存的时候,进行精准的贪心算法明显是不可行的,所以需要近似算法。精确贪心算法相当于,对于连续变量当中的所有分隔,都作为分割点的候选。一个很自然的近似算法就是,只从当中选择一个子集作为分割点的候选,就是将连续变量给映射到一个个的桶当中,然后基于这些通的统计信息,来选择分割点。具体算法如下图所示,只需要将每一个桶,作为其中的一个样本来思考就可以了。

那么如何分桶实际上就是近似算法的关键所在,XGBoost的论文当中提出了两种方案:
当然从结果上来看,当全局方法的候选数量提升之后,也同样可以获取和局部方法差不多的表现。
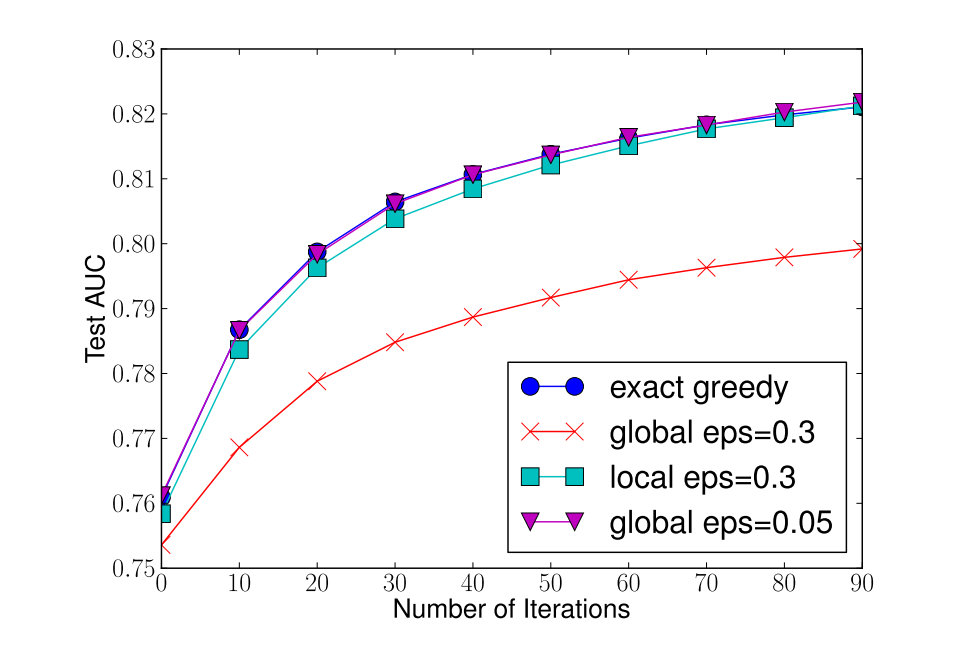
对于具体如何选择分割点,论文提出了一个叫做Weighted Quantile Sketch的方法。使用Dk={(x1k,h1),(x2k,h2),…,(xnk,hn)}来表示第k个特征以及样本的二阶梯度,定义一个rank函数为rk:R→[0,+∞)如下所示:
rk(z)=∑(x,h)∈Dkh1(x,h)∈Dk,x<z∑h
对于之前算法当中所提到的ϵ,实际上就是要找到一系列的分割点{sk1,sk2,…,skl},使得:
∣rk(sk,j)−rk(sk,j+1)∣<ϵ
所以ϵ相当于一个度量采样点数量的值,ϵ越小,对应的分割点就越多,数量近似为1/ϵ。 而采用二阶梯度作为分割依据的根据,来源于之前的目标函数:
L~(t)=i=1∑n[gift(xi)+21hift2(xi)]+Ω(ft)=i=1∑n21hi(ft(xi)−higi)2+Ω(ft)+constant
之前的目标函数,实际上可以看作是一个以hi为权重的加权平方损失,所以采用hi来计算分割点。对于Weighted Quantile Sketch的具体实现,论文提供了一种新的数据结构,具体在论文附录当中,有兴趣的读者可以自己查看。
XGBoost对于稀疏特征有特殊的优化。稀疏矩阵的产生原因可能是缺失值,又或者One-Hot方法的使用。对于稀疏数据可以做一些特殊处理,我们可以将随意地分到左子树或者右子树,或者可以从数据当中来确定子树的分配方式。

如上述算法所示,只对于对应特征没有缺失值的样本来考虑分割点,而对于所有缺失值,考虑统一分到左边或者统一分到右边。对于两种情况以及所有分割点,取当中能够获得最大增益的作为最终选择的节点分裂方式。