这是关于Optiver Trivia Night的记录(主要关于最开始的Quiz部分),最开始部分为一个大约30min的Quiz,之后为Optiver实习项目相关的介绍和答疑。其中Optiver是一家全球顶级的做市商,具体信息可以参见官网。
Quiz部分的得分与正确率和答题速度相关,在大家都答对题目的情况下,答题更快的可以获得更高的得分。
第一名可以获得Optiver的终面机会,前五名获得AirPods。
题目总量为四十道,总共用时30min,总共分为几类问题:
- Quick Math (5s) - 基本的数学运算,难度大概在三位数加减法和两位数乘法的水平,重点可能在于时间限制较为紧迫
- Fun Facts (20s) - 询问一些现实生活当中的数字,考察量级估计和现场搜索的能力
- Find Pattern (30s) - 图形找规律,填写下一项是什么
- Easy Brain Teasers (30s) - 较为简单,基本上是基本数学直觉的考察
- Sequence (60s) - 数列找规律,填写下一项是什么
- Medium Brain Teasers (60s) - 普通的概率问题
- Hard Brain Teasers (120s) - 较复杂一些的概率问题
最后排名为Rank 25/150,感觉如果有一定的面试准备的话应该进前十问题不是很大。大部分题目并不会很难,提供足够的时间都能够做的出来,只是在Quiz的情况下会有很强的时间紧迫感。
以下是一部分的题目记录,其中由于Quick Math部分时间过于紧张,所以基本上没有保存到截图。
部分Fun Facts可能会随着时间改变,这里的结果以2021年9月作为参考
No. 7 (Hard Brain Teasers)
10个人围成一个圈。每个人可以拍一拍左侧或者右侧的人,请问被拍的人的个数的期望是多少?
- 2.5
- 5
- 7.5
- 8.36
Answer: C
No. 12 (Sequence)
2,3,7,16,65,?
序列的下一个数字是什么?
- 321
- 81
- 122
- 179
Answer: A
No. 13 (Fun Facts)
以下最接近沪深市场一天的流通量的量级的是(以RMB计价)?
- 10b/day (一百亿)
- 100b/day (一千亿)
- 1t/day (一万亿)
- 10t/day (十万亿)
Answer: C
No. 14 (Sequence)
15,29,56,108,208,?
序列的下一个数字是什么?
- 400
- 416
- 438
- 386
Answer: A
No. 15 (Fun Facts)
世界上最重的猪有多重
- 1157kg
- 1312kg
- 694kg
- 866kg
Answer: A
No.16 (Hard Brain Teasers)
有5封不同的信来自5个不同的人。如果我们随机分发信件,没有一个人收到Ta自己的信的概率是多少?
- 4/5
- 11/30
- 7/20
- 5/12
Answer: B
No. 17 (Medium Brain Teasers)
地上有一个10cm * 10cm的无限大网格,你随机扔一枚直径为1cm的硬币。问硬币碰到网格线上的概率是多少?
- 50%
- 25%
- 19%
- 11%
Answer: C
No. 18 (Find Pattern)
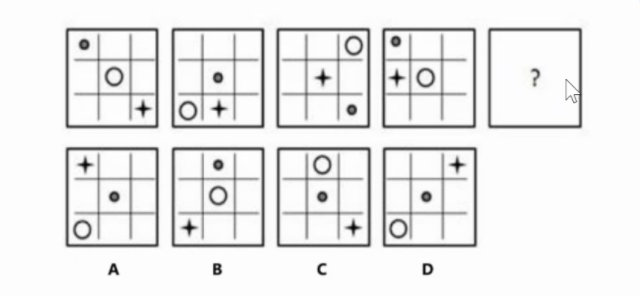
Answer: A
No. 19 (Medium Brain Teasers)
红色柱体的高度是多少?
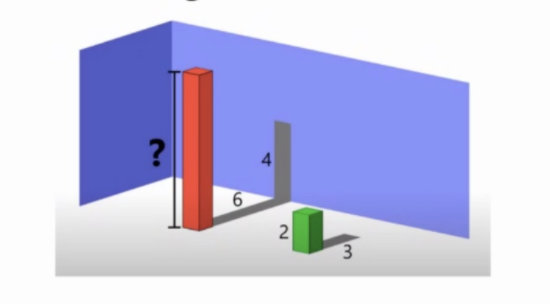
- 8
- 10
- 20/3
- 15
Answer: A
No. 21 (Easy Brain Teasers)
下列的哪一个不是素数?
- 257
- 289
- 157
- 349
Answer: B
No. 22 (Medium Brain Teasers)
你有机会可以对数字1~6进行下注,投掷三个骰子。如果你选择的数字出现一次,你获得$1;如果两次,你获得$2;如果三次,你获得$3。你所获得金额的期望是多少?
- $0
- $0.5
- $1
- $1/3
Answer: B
No. 23 (Fun Facts)
哪一个整数区间当中包含最多的素数?
- [1, 100]
- [101, 200]
- [201, 300]
- [301, 400]
Answer: A
No. 24 (Hard Brain Teasers)
(1+√2)3000小数点后第100位的数字是多少?
提示:(1+√2)3000+(1−√2)3000 是一个整数
- 0
- 1
- 4
- 9
Answer: D
No. 25 (Medium Brain Teasers)
你站在地球的表面上,你往南走1英里,往西走1英里,往北走1英里,最后你停留在了你开始的地方。地球上有多少点可以让你完成以上的行为?
- 0
- 1
- 2
- 无穷多个
Answer: D
No. 26 (Sequence)
91,85,94,83,97,81,?,79
序列的下一个数字是什么?
- 80
- 100
- 102
- 95
Answer: B
No. 27 (Hard Brain Teasers)
考虑一个平面上的5个点,在所有的点之间两两连线,你拥有了x条直线。那么以下哪个不可能是x的值?
- 5
- 6
- 7
- 8
Answer: C
No. 28 (Easy Brain Teasers)
一个立方体的面、棱、顶点数的总和是多少?
- 26
- 28
- 30
- 24
Answer: A
No. 29 (Sequence)
99,18,36,9,18
序列的下一个数字是什么?
- 36
- 27
- 9
- 3
Answer: C
No. 31 (Fun Facts)
一个标准的奥林匹克游泳池(25m * 50m * 2m) 有多少升水?
- 250
- 25000
- 2500000
- 250000000
Answer: C
No. 34 (Hard Brain Teasers)
一个密码只能以字母而不能以数字开头,那么po88p881有多少种排列可以是密码?
- 315
- 420
- 525
- 840
Answer: A
No. 35 (Fun Facts)
火星的平均温度是多少?
- -100°C
- -60°C
- -20°C
- 20°C
Answer: B
No. 36 (Medium Brain Teasers)
考虑一个时钟,一天当中时针和分针会重合多少次?
- 22
- 23
- 24
- 26
Answer: A
No. 37 (Easy Brain Teasers)
如果下列命题有正确的话,哪一个命题是正确的?
- 在列表中至少有1个命题是错误的
- 在列表中至少有2个命题是错误的
- 在列表中至少有3个命题是错误的
- 在列表中至少有4个命题是错误的
Answer: A
No. 38 (Sequence)
−3,3,27,69,129,?
序列的下一个数字是什么?
- 178
- 207
- 312
- 268
Answer: B
No. 39 (Find Pattern)
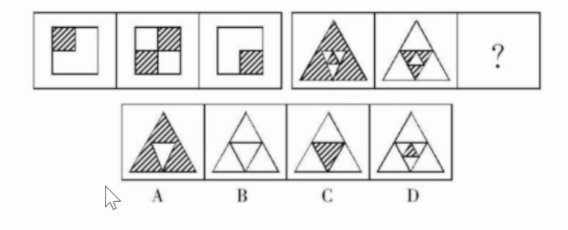
Answer: B
No. 40 (Hard Brain Teasers)
一个国际象棋棋盘的每个小正方形边长都为2。请问在棋盘上作一个圆,能够使得整个圆的圆周都在黑色方形内部的最大的圆半径为多少?
- Sqrt(2)
- 2
- Sqrt(10)
- Sqrt(34)
Answer: C