因为就是准备笔试时候自己刷了刷题,所以基本都只在本地跑过了样例
A. 第n小的质数
Implementation
1 |
|
B. 潜伏者
Implementation
1 |
|
C. 逃离迷宫
BFS
1 |
|
D. 跑步
DP
1 |
|
E. What time is it?
Implementation
1 |
|
F. Sorting It All Out
Sortings
1 |
|
G. Rails
Stack
1 |
|
H. The Rotation Game
IDA*
1 |
|
因为就是准备笔试时候自己刷了刷题,所以基本都只在本地跑过了样例
Implementation
1 |
|
Implementation
1 |
|
BFS
1 |
|
DP
1 |
|
Implementation
1 |
|
Sortings
1 |
|
Stack
1 |
|
IDA*
1 |
|
在神经网络训练过程当中,如果是利用jupyter-notebook来进行代码编写的话,可能断开之后不会看到输出的结果。利用logging模块可以将内容同时输出到文件和终端,首先定义构造logger的函数内容如下:
1 | import logging |
之后在训练流程当中通过以上的函数生成logger,再采用info方法进行保存就可以了:
1 | logger = get_logger('./train.log') |
正常的分布式训练方法会传递所有的梯度,但是实际上,可能有超过99%的梯度交换都是无关紧要的,所以可以通过只传送重要的梯度来减少在深度学习的分布式训练当中通信带宽。DGC方法通过稀疏更新来只传递重要的梯度,同时利用Momentum Correction,Gradient Clipping等方法来预防不收敛的情形,保证分布式训练不会影响最终的模型准确性。
那么如何来衡量一个梯度的重要性呢,显然如果一个网络节点的梯度大小绝对值更大的话,它会带来的权重更新就会更大,那么对于整个网络的变化趋势而言,就是更为重要的。在DGC方法当中,认为绝对值大小超过某一阈值的梯度为重要的梯度。但是如果只传递此类重要梯度的话,和损失函数的优化目标会存在一定程度上的差距,所以出于减少信息损失的考虑,把剩下不重要的梯度在本地进行累积,那么只要时间足够,最终累积梯度就会超过所设定的阈值,进行梯度交换。
由于仅仅是数值较大的梯度进行了立即传递,较小的梯度在本地进行累积更新,所以能够极大减少每个step交换梯度所需要的通信带宽。那么需要考虑的一点是这种本地梯度累积的方法是否会对于优化目标产生影响,计为损失函数,可以首先分析一个step的更新公式如下:
如果在本地进行梯度累积,那么假设在经历过个step之后才进行梯度交换,那么更新公式可以修改为如下形式:
那么如上式所示,可以发现当针对于大小进行学习率缩放之后,在分子分母的可以消去,于是总体可以看成是人为的将batch大小从提升到了。所以直观上本地梯度累积的方法可以看成是随着更新时间区间的拉长来增大训练batch的大小,同时对于学习率进行同比例缩放,并不会影响最终的优化目标。
如果直接针对于普通的SGD采用以上的DGC方法,那么先让当更新十分稀疏,即间隔区间长度很大的时候,可能会影响网络的收敛。所以又提出了Momentum Correction和Local Gradient的方法来缓解对于收敛性质的伤害。
最普通的动量方法如下所示,其中的值即为动量。
事实上最终进行本地的梯度累积和更新都是利用左侧的来代替原始梯度的,于是可以得到参数更新的表达式如下,假设稀疏更新的时间间隔为。
对比没有动量修正的更新方法如下:
可以发现实际上缺少了的求和项,当为0的时候得到的就是普通情形。直观上来理解可以认为越早的梯度提供了一个更大的权重。这是合理的是因为在进行梯度交换更新之后,本地参数和全局参数是相同的,而随着本地更新时间的增加,本地参数同全局参数的差异会越来越大,那么对于所得到梯度全局的影响的泛化性应当越来越差,所以理应当赋予一个更小的权重。
梯度裁剪即在梯度的L2范数超过一个阈值的时候,对梯度进行一个缩放,来防止梯度爆炸的问题。通常而言,分布式训练的梯度裁剪是在进行梯度累积之后进行,然后利用裁剪过后的梯度进行更新,并分发新的网络权重给其他的训练节点。但是在DGC方法中将梯度的传送稀疏化了,同时存在本地更新,这种先汇总后裁剪的方法就不可取。这里的梯度裁剪是再将新的梯度累加到本地之前就进行。
需要做一个假设如下,假设个训练节点的随机梯度为独立同分布,都有着方差,那么可以知道所有训练节点的梯度汇总之后,总的梯度应当有方差,于是单个运算节点的梯度和总梯度有关系如下:
所以应当对于所设定的阈值进行一个缩放,假设原本设定的梯度的L2范数的阈值为的话,那么对于每一个训练节点而言,其阈值应当为:
其中的表示的是训练节点的个数。
事实上由于梯度在本地进行累积,可能更新的时候梯度是过时的了(stale),在实验中发现绝大部分的梯度都在600~1000次迭代之后才会更新。文章中提出了两种方法来进行改善。
将记作在本地的梯度累积:
可以利用Momentum Factor Masking的方法,这里简单起见,对于梯度和累积梯度采用同样的Mask:
这个方法会让过于老的梯度来停止累积,防止过于旧的梯度影响模型的优化方向。
在训练的最初期,模型往往变化的特别剧烈,这时候采用DGC的问题如下:
所以采用Warm-up的训练trick,在一开始采用更低的学习率,同时采用更低的稀疏更新的阈值,减少被延缓传递的参数。这里在训练的最开始采用一个很低的学习率,然后以指数形式逐渐增加到默认值。
Ashish has a tree consisting of nodes numbered to rooted at node . The -th node in the tree has a cost , and binary digit is written in it. He wants to have binary digit written in the -th node in the end.
To achieve this, he can perform the following operation any number of times:
He wants to perform the operations in such a way that every node finally has the digit corresponding to its target.
Help him find the minimum total cost he needs to spend so that after all the operations, every node has digit written in it, or determine that it is impossible.
Input
First line contains a single integer denoting the number of nodes in the tree.
-th line of the next lines contains 3 space-separated integers , , — the cost of the -th node, its initial digit and its goal digit.
Each of the next n−1 lines contain two integers , , meaning that there is an edge between nodes and in the tree.
Output
Print the minimum total cost to make every node reach its target digit, and −1 if it is impossible.
Examples
input
1 | 5 |
output
1 | 4 |
input
1 | 5 |
output
1 | 24000 |
input
1 | 2 |
output
1 | -1 |
Note
The tree corresponding to samples and are:
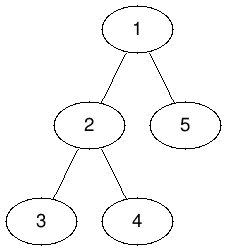
In sample , we can choose node and for a cost of and select nodes , shuffle their digits and get the desired digits in every node.
In sample , we can choose node and for a cost of , select nodes and exchange their digits, and similarly, choose node and for a cost of , select nodes and exchange their digits to get the desired digits in every node.
In sample , it is impossible to get the desired digits, because there is no node with digit initially.
有一颗树,树根为节点1,每个节点有三个属性,代表当前节点的状态,代表当前节点需要变成的状态,代表修改节点状态所需要的花费。
现在能够进行一种操作:
选择一颗以为根节点的子树,任意的修改其子树中的个节点的状态(互相交换),这个操作的花费为。
现在需要求解使树中所有节点都能变成目标状态所需要的最小开销,如果不存在则进行判定。
首先可以知道,如果一个节点的父亲节点为,且有,那么所有以节点为根的子树上涉及到的操作都可以移动到其父节点上进行,可以对整棵树进行的操作而不改变本身的结果。
完成以上操作之后,根节点到叶子结点的值实际上就是一个单调递减的序列,可以从叶子结点往根节点进行遍历,一旦当前子树上存在可以操作的成对节点就进行操作。
时间复杂度为遍历树的时间复杂度。
1 |
|
当是ENV_TYPE_FS的时候提供读写的权限,对于普通的Env则不提供权限。
1 | // If this is the file server (type == ENV_TYPE_FS) give it I/O privileges. |
为block分配一个页面,并且将block的内容读入。首先将addr进行对齐,这里由于page的大小和block的大小相同,所以怎样对齐都是可以的。之后利用sys_page_alloc()系统调用来进行页面分配,然后利用ide_read()进行内容的读取。注意的是ide_read()是以sector为单位进行读取的,是512个byte,同block的大小是8倍的关系,所以需要进行一个小小的处理。
1 | // Allocate a page in the disk map region, read the contents |
当必要的时候,需要将Block写回磁盘,而必要的时候就是可写页面被修改的时候,所以这里首先的判断条件就应当是当前所对应的block是被映射了的,并且是dirty的。在调用ide_write()写回之后,需要重新进行一次映射来消除掉dirty位。这样可以避免多次进行flush,访问磁盘占用大量的时间。
1 | // LAB 5: Your code here. |
首先观察free_block()函数,可以发现每一位标志着一个block的状态,其中1表示为空闲,0表示为忙碌。访问的方式如第八行所示。
1 | // Mark a block free in the bitmap |
那么仿照就可以完成alloc_block(),对所有的block进行一个遍历,如果发现free的就进行分配,在bitmap中标志为0,之后立即利用flush_block()将将修改写回磁盘,并且返回blockno。
1 | // Search the bitmap for a free block and allocate it. When you |
这里的寻址实际上类似于lab2当中虚拟内存的寻址,不过在这里的设计上只有一个indirect的链接,所以实现起来相对简单很多。
1 | // Find the disk block number slot for the 'filebno'th block in file 'f'. |
通过file_block_walk()找到对应的pdiskbno,如果为0,那么就进行分配,否则的话利用diskaddr()转换成地址。成功就返回0。
1 | // Set *blk to the address in memory where the filebno'th |
实际上就是针对于file_read()的一层封装,首先利用openfile_lookup()找到对应的文件,然后调用file_read()进行读入,之后调整文件的指针,并返回读入的大小。
1 | // Read at most ipc->read.req_n bytes from the current seek position |
serve_write()的逻辑类似于serve_read(),具体代码如下:
1 | // Write req->req_n bytes from req->req_buf to req_fileid, starting at |
devfile_write(0)同样可以仿照devfile_read()进行完成。
1 | // Write at most 'n' bytes from 'buf' to 'fd' at the current seek position. |
首先判断得到env,然后从18~20行依次为,开启中断,设置IOPL为0,将保护权限设置为3(CPL 3)。
1 | // Set envid's trap frame to 'tf'. |
关于duppage()的修改,可以注意到直接只需要在可写页面修改为COW的时候进行PTE_SHARE的标志位判断就可以了,只在第11行处添加一个判断,其余内容同lab4中完全相同。
1 | static int |
从UTEXT到UXSTACKTOP的所有共享页面将其映射复制到子进程的地址空间即可,代码类似于lab4里面的fork()
1 | // Copy the mappings for shared pages into the child address space. |
添加对应的分发入口即可:
1 | // Handle keyboard and serial interrupts. |
重定向输出流的代码如下:
1 | case '>': // Output redirection |
仿照就可以完成输入流的重定向:
1 | // LAB 5: Your code here. |
到这里可以达到150/150的满分:
1 | internal FS tests [fs/test.c]: OK (1.0s) |
Challenge的要求即为清空掉所有的没有被访问的页面。那么对于单个页面,只需要调用flush_block(),之后通过系统调用unmap就可以了。evict_policy()即对于所有的block做一个便利,清除所有从未被访问过的页面。具体代码内容如下:
1 | // challenge |
往常的论文对于训练过程中的方法使用并不是非常关注,通常只能从代码中去寻找训练过程所采用的trick。
这篇文章介绍了一些训练图像分类CNN网络的trick,使用这些方法可以显著的提高分类网络的准确性。同时更好的准确性在迁移到object detection和semantic segmentation等任务上也会有更好的效果。
利用随机梯度下降的方法来训练神经网络的基本流程如下所示,首先先对于baseline情况的超参数进行一个假定,之后再讨论优化的方法:

使用更低的精度和更大的batch size可以使得训练更加高效,这里提供了一系列这样的方法,有的可以同时提升准确率和训练速度。
使用更大的batch size可能会减慢训练进程。对于凸优化问题,随着batch size的上升,收敛速率会下降,在神经网络当中也有相同的情况。在同样数目的epoch情况下,用大的batch训练的模型在验证集上的效果会更差。
下面有四个启发式的方法用来解决上面提到的问题:
理论上来说,从估计梯度的角度,提升batch size并不会使得得到梯度的大小期望改变,而是使得它的方差更小。所以可以对于学习率进行成比率的缩放,能够使得效果提升。
比如在当batch size为256的时候,选用0.1的学习率。
那么当采用一个更大的batch size,例如的时候,就将学习率设置为。
在训练开始的时候,所有参数都是随机设置的,离最终结果可能会非常远,所以采用一个较大的学习率会导致数值上的不稳定,所以可以考虑在最开始使用一个很小的学习率,再慢慢地在训练较为稳定的时候切换到初始学习率。
例如,如果我们采用前个batch来进行warm up的话,并且学习率的初值为,那么在第个batch,,就选用大小为的学习率。
ResNet是有很多个residual block堆叠出来的,每个residual block的结果可以看成是,而block的最后一层通常是BN层,他会首先进行一个standardize,得到,然后在进行一个缩放,其中和都是可学习的参数,通常被初始化为1和0。
可以考虑在初始化的时候,将所有的参数都设置成0,这样网络的输出就和他的输入相同,这样可以缩小网络,使得在最开始的时候训练变得更简单。
weight decay通常被用于所有可学习的参数来防止正则化,这里的trick就是只作用于权重,而不对bias包括BN层当中的和做decay。
通常是采用FP32来进行训练的,但是大量的TPU在FP16上面的效率会高很多,所以可以考虑采用FP16来进行训练,能够达到几倍的加速。
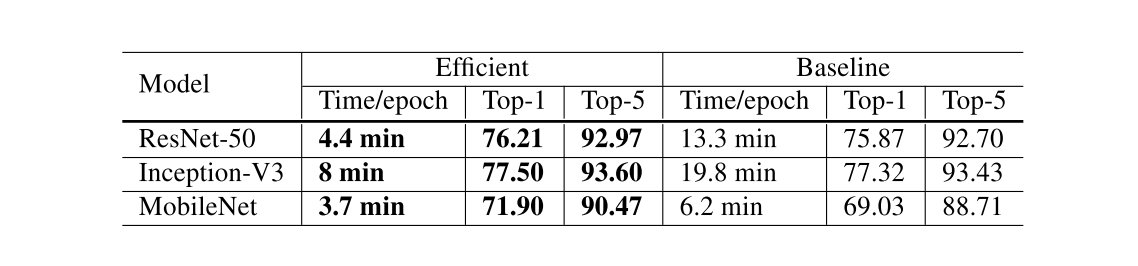
实验结果如上,其中Baseline的设置为,采用FP32,Efficient的设置为,采用FP16。
原本的ResNet网络结构如图所示:
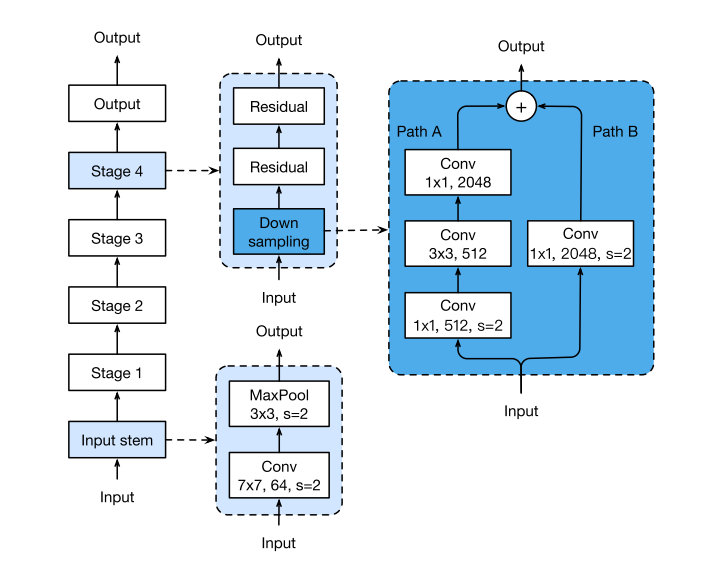
这里不多做介绍,文章提出了三种针对ResNet修改方式,分别记作ResNet-B/C/D,能够得到一定程度上的准确率提升。
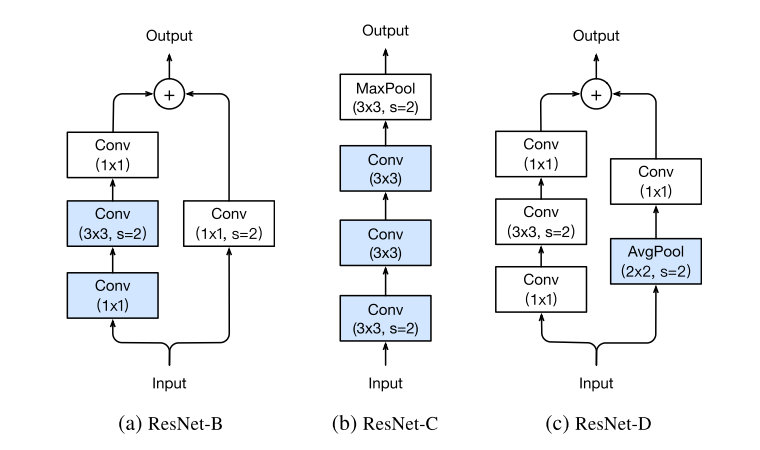
第一个所做的就是改变了downsampling的方式,由于如果采用卷积同时选择stride为2的话,会丢失的信息,这里在的的卷积层来downsampling,理论上所有信息都会被接受到。
一个发现就是卷积计算量随卷积核大小变化是二次多项式级别的,所以利用三层的卷积来替代的卷积层。
从ResNet-B的角度更进一步,旁路也同样会有信息丢失的问题,所以将一层的卷积修改成一层Average Pooling再加上一层卷积,减少信息的丢失。
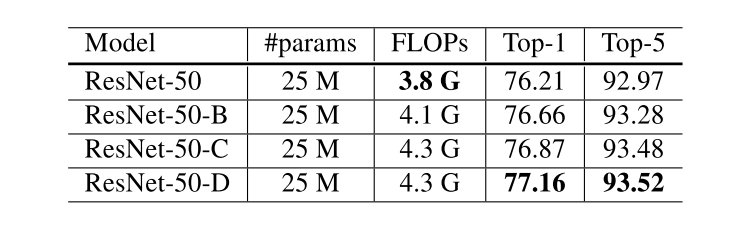
可以看到三者对于原始的ResNet结构准确率都有一定程度上的上升。
采用最广泛的策略是指数衰减。这里提供的一种方法是利用cosine函数进行衰减,忽略掉最开始进行warmup的部分,假设一共有个batch,那么在第个batch上,学习率为:
其中就是初始的学习率,对比结果如下:
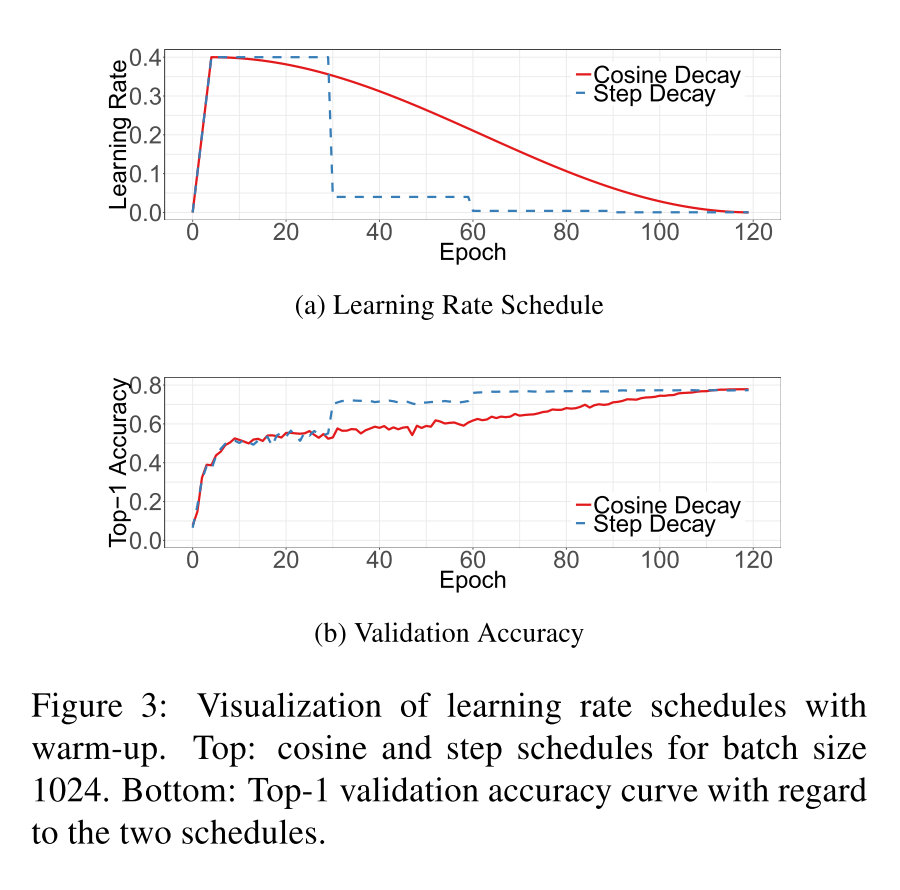
可以看到cosine decay在一开始和最终学习率下降的比较慢,在中间接近于线性的衰减。
对于分类任务,最后一层通常都是通过一个softmax函数来得到预测的概率,对于第类的结果:
我们在学习过程当中最小化的是负的cross entropy:
只有当的时候为1,其余时候为0,于是就等价于:
要达到最小化的效果应当有,同时使得其他种类的尽可能小,换言之,这样会倾向于让预测结果趋于极端值,最终导致overfit。
label smoothing的思想就是将真实概率构造为:
其中是一个小的常量,此时的最优解为:
其中是一个实数,这会使得最终全连接层的输出会趋向于一个有限值,能够更好地泛化。
里面的部分就是正确分类和错误分类之间的gap,它随着的增大不断缩小,当的时候,实际上就是均匀分布,gap就为0了。
关于gap的可视化如下:
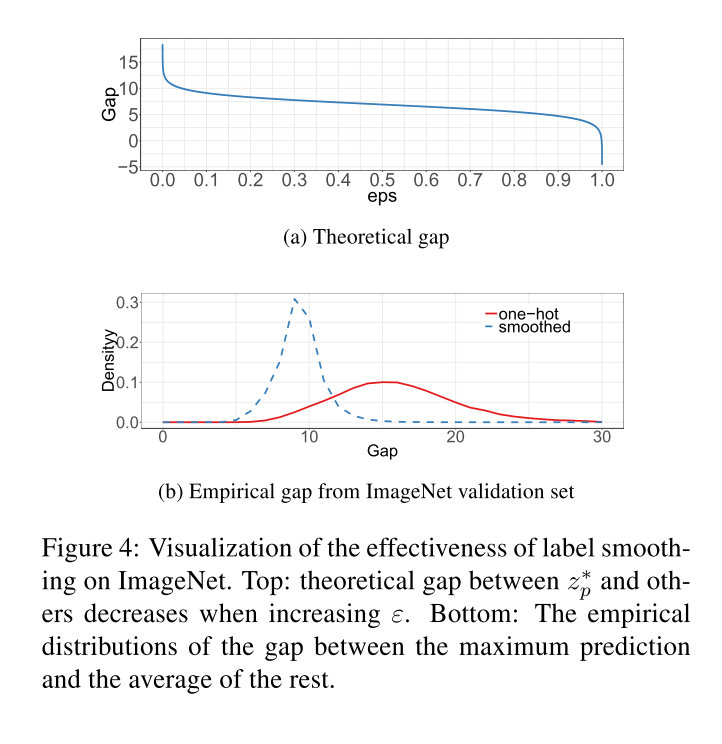
可以发现smooth之后gap总体均值变小,并且大gap的极端值情况有效减少了。
知识蒸馏中,我们尝试用一个学生模型来学习高准确率的老师模型里面的知识。方法就是利用一个distillation loss来惩罚学生模型偏离老师模型的预测概率。利用作为真实概率,和分别作为学生网络和老师网络全连接层的输出,利用负的cross entropy作为loss,总的loss可以写成:
其中为温度超参数,使得softmax函数的输出变得更为平滑。
作为一个数据增强的手段,每次随机选择两个样本和。然后对两个样本加权来作为新的样本:
其中是一个从中采样出来的数,在mixup中只对于新的样本来进行训练。
A monopole magnet is a magnet that only has one pole, either north or south. They don’t actually exist since real magnets have two poles, but this is a programming contest problem, so we don’t care.
There is an grid. Initially, you may place some north magnets and some south magnets into the cells. You are allowed to place as many magnets as you like, even multiple in the same cell.
An operation is performed as follows. Choose a north magnet and a south magnet to activate. If they are in the same row or the same column and they occupy different cells, then the north magnet moves one unit closer to the south magnet. Otherwise, if they occupy the same cell or do not share a row or column, then nothing changes. Note that the south magnets are immovable.
Each cell of the grid is colored black or white. Let’s consider ways to place magnets in the cells so that the following conditions are met.
Determine if it is possible to place magnets such that these conditions are met. If it is possible, find the minimum number of north magnets required (there are no requirements on the number of south magnets).
Input
The first line contains two integers and () — the number of rows and the number of columns, respectively.
The next lines describe the coloring. The -th of these lines contains a string of length , where the -th character denotes the color of the cell in row and column . The characters “#” and “.” represent black and white, respectively. It is guaranteed, that the string will not contain any other characters.
Output
Output a single integer, the minimum possible number of north magnets required.
If there is no placement of magnets that satisfies all conditions, print a single integer −1.
Examples
input
1 | 3 3 |
output
1 | 1 |
input
1 | 4 2 |
output
1 | -1 |
input
1 | 4 5 |
output
1 | 2 |
input
1 | 2 1 |
output
1 | -1 |
input
1 | 3 5 |
output
1 | 0 |
Note
In the first test, here is an example placement of magnets:
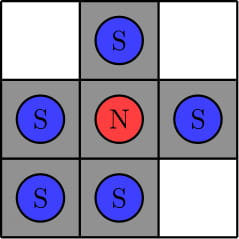
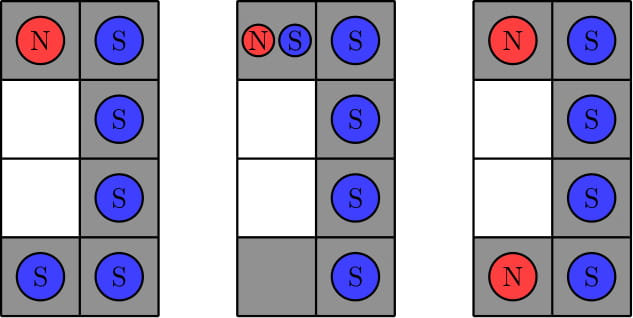
In the second test, we can show that no required placement of magnets exists. Here are three example placements that fail to meet the requirements. The first example violates rule 3 since we can move the north magnet down onto a white square. The second example violates rule 2 since we cannot move the north magnet to the bottom-left black square by any sequence of operations. The third example violates rule 1 since there is no south magnet in the first column.
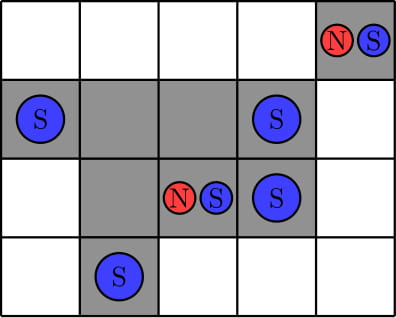
In the third test, here is an example placement of magnets. We can show that there is no required placement of magnets with fewer north magnets.
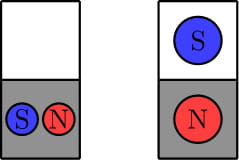
In the fourth test, we can show that no required placement of magnets exists. Here are two example placements that fail to meet the requirements. The first example violates rule 1 since there is no south magnet in the first row. The second example violates rules 1 and 3 since there is no south magnet in the second row and we can move the north magnet up one unit onto a white square.
In the fifth test, we can put the south magnet in each cell and no north magnets. Because there are no black cells, it will be a correct placement.
有S和N两种磁铁,可以互相吸引,每次可以选择一个S和一个N激活,使得N向S方向移动,问需要有多少N磁铁可以满足(不限制S磁铁的数量)
如果无法满足以上三条规则,那么就输出-1。
首先排除所有不可能满足的情况:
综上,放置磁铁的方式为将S磁铁放置在所有黑色块中和空白行列相交处。
N磁铁需要每一个连通区域放置一个,由于N磁铁不能跨区域移动,所以这种放置方式是最优的。
1 |
|
Calculate the number of ways to place rooks on chessboard so that both following conditions are met:
An empty cell is under attack if there is at least one rook in the same row or at least one rook in the same column. Two rooks attack each other if they share the same row or column, and there are no other rooks between them. For example, there are only two pairs of rooks that attack each other in the following picture:
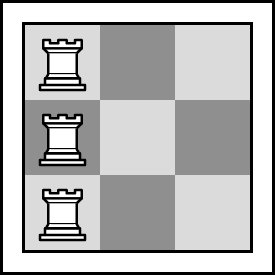
One of the ways to place the rooks for and
Two ways to place the rooks are considered different if there exists at least one cell which is empty in one of the ways but contains a rook in another way.
The answer might be large, so print it modulo 998244353.
Input
The only line of the input contains two integers and (; ).
Output
Print one integer — the number of ways to place the rooks, taken modulo 998244353.
Examples
input
1 | 3 2 |
output
1 | 6 |
input
1 | 3 3 |
output
1 | 0 |
input
1 | 4 0 |
output
1 | 24 |
input
1 | 1337 42 |
output
1 | 807905441 |
rook可以对同一行和同一列攻击,提供两个数和,求在的棋盘上放置个rook使得:
的放置方法总数。
由于所有地方都需要被攻击到,那么就相当于一定是每个行都有一个rook或者每个列都有一个rook.本质上是一个排列组合问题,可以发现,行和列实际上是对称的,所以只需要考虑行列当中的一种。
假设每个行上都有一个rook,如果,那么必然是个rook分布在个列上。对应的排列方法一共有:
从上面的分析也可以发现,如果,那么不存在符合的情况。再注意当的时候需要,需要乘2,而的时候直接作为结果就可以了。
1 |
|
这个建立映射的函数实际上和kern/pmap.c当中的boot_alloc()存在类似的地方,都是利用一个静态的变量来保存当前分配空间的起始地方,然后不断的增长进行分配。由于base每次都会增长,所以每次都是映射新的页面。
1 | // |
修改page_init()的内容如下,只是增加一个特殊处理:
1 | // case 1: |
只要在第6行添加一个判断就可以了。
之后执行make qemu就可以看到如下的check都已经成功了。
1 | check_page_free_list() succeeded! |
宏MPBOOTPHYS的作用是将高地址转换为低地址,使得可以在实模式下进行访问。在boot.S当中,本来就已经被链接到了低地址,不需要进行转换,而mpentry.S的代码都位于KERNBASE的上方,所以需要手动的利用MPBOOTPHYS宏进行转换。
这里直接利用一个循环进行映射,由于每个栈之间是存在一个Gap的,所以只有[kstacktop_i - KSTKSIZE, kstacktop_i)部分需要进行映射。
1 | // Modify mappings in kern_pgdir to support SMP |
这里实际上就是用thiscpu来替换原本的全局变量,使得本来是在lab3当中对于单CPU适用的情况可以适用于多个CPU的情形。
1 | // Initialize and load the per-CPU TSS and IDT |
根据文档的描述在四个所需要插入大内核锁的地方进行lock_kernel()和unlock_kernel()的操作。
In i386_init(), acquire the lock before the BSP wakes up the other CPUs.
1 | // Acquire the big kernel lock before waking up APs |
In mp_main(), acquire the lock after initializing the AP, and then call sched_yield() to start running environments on this AP.
1 | // Now that we have finished some basic setup, call sched_yield() |
In trap(), acquire the lock when trapped from user mode. To determine whether a trap happened in user mode or in kernel mode, check the low bits of the tf_cs.
1 | // Trapped from user mode. |
In env_run(), release the lock right before switching to user mode. Do not do that too early or too late, otherwise you will experience races or deadlocks.
1 | lcr3(PADDR(e->env_pgdir)); |
从trapentry.S当中可以看到,在调用trap()之前(还没有获得大内核锁),这个时候就已经往内核栈中压入了寄存器信息,如果内核栈不分离的话,在这个时候切换就会造成错误。
这里的调度方法实际上是一个非常暴力的轮询,如果找到了一个状态是ENV_RUNNABLE的进程那么就让他上CPU。如果找了一圈都没有找到合适的进程的话,就看起始进程,如果它本来就在当前CPU上运行的话,那么就继续运行,否则的话一个进程不能在两个CPU上同时运行,就调用sched_halt()。
1 | // Choose a user environment to run and run it. |
在syscall()当中添加新的系统调用的分发:
1 | case SYS_yield: |
在mp_main()当中调用sched_yield()。
1 | // Setup code for APs |
看env_run()当中对应代码部分如下:
1 | if(curenv != NULL && curenv->env_status == ENV_RUNNING) |
在lcr3()前后都能够正常对e进行解引用是因为,在设置env_pgdir的时候是以kern_pgdir作为模板进行修改的,e地址在两个地址空间中是映射到同一个物理地址的,所以这里进行解引用的操作不会有问题。
保存寄存器信息的操作发生在kern/trapentry.S当中:
1 | .global _alltraps |
恢复寄存器的操作发生在kern/env.c的env_pop_tf()当中:
1 | void |
这里每一个系统调用的主要内容都不复杂,主要的是进行许多参数有效性的检查,只需要按照注释中的内容进行参数检查就可以。
传建一个子进程,在子进程中返回值为0,在父进程中返回的是子进程的id,先将子进程的状态设置成ENV_NOT_RUNNABLE之后再进行地址空间的复制之后可以会再设置成可运行的状态。
1 | // Allocate a new environment. |
就是23行处的设置env_status。但是这个系统调用只能在ENV_RUNNABLE和ENV_NOT_RUNNABLE当中设置。
1 | // Set envid's env_status to status, which must be ENV_RUNNABLE |
在envid的地址空间中分配一个页面,除去类型检查之外所做的内容就是page_alloc()和page_insert()。
1 | // Allocate a page of memory and map it at 'va' with permission |
37行之前为参数的检查,39行之后为具体执行的内容,实际上完成的就是将srcenvid对应进程的地址空间中的srcva页面映射到dstenvid对应进程的地址空间中的dstva页面。
1 | // Map the page of memory at 'srcva' in srcenvid's address space |
实际上就是19行处的page_remove()操作,剩下的是参数的有效性检查。
1 | // Unmap the page of memory at 'va' in the address space of 'envid'. |
最后要在syscall()当中添加分发的方法:
1 | case SYS_exofork: |
又是一个系统调用的设置,当使用envid2env()的时候需要进行权限的检查,如果能够正常的得到env的话就设置对应的env_pgfault_upcall。同样要在syscall()当中添加新的case。
1 | // Set the page fault upcall for 'envid' by modifying the corresponding struct |
这里关于page_fault_handler()在有env_pgfault_upcall的情况下,分为两种情况,如果本身在Exception Stack里面的话,那么需要空出一个word的大小,具体的作用在后面Exercise 10会体现。否则的话直接将结构体压在Exception Stack的底部就可以了。
1 | // LAB 4: Your code here. |
第8行为写入的权限检查,之后9-14行为struct UTrapframe整个结构体的压入,然后修改curenv里面的内容,转入env_pgfault_upcall当中执行。
如果没有env_pgfault_upcall的话,那么就执行env_destroy()的操作。
Exception Stack中的结构如下所示:
1 | // trap-time esp |
补全的_pgfault_upcall的代码如下:
1 | // LAB 4: Your code here. |
这里要实现栈切换同时需要保存%eip,首先在2、3行,将%eip取出放入%edi中,%esp取出放入%esi中,之后将%esp向下延伸一个word的大小,然后把%eip填入,之后将修改后的%esp放回保存的位置。
这样最终得到的%esp所指向的栈顶第一个元素就是我们之前所保存的%eip寄存器的值,就同时完成了栈的切换和%eip的恢复。后面就是不断退栈恢复寄存器的过程了,非常简单。
这里如果是在Exception Stack当中的重复调用,由于之前确保重复调用会在每两个结构之间留下一个word大小的gap,这个空隙就可以填入%eip保证以上的upcall在重复调用的情况下也能正常工作。
如果是第一次进行调用的话,那么需要进行初始化的设置,即给Exception Stack分配空间(17行),同时设置pgfault_upcall(19行)。
1 | // |
pgfault() 可以参照dumbfork.c里面的duppage(),事实上dumbfork就是全部都进行一个复制,而COW的fork()只有在写入写时复制页面的时候才会进行复制,所以这里首先进行一个检查,看是不是写入一个COW页面所产生的错误。如果是的话,就分配一个新的页面并且将整个页面的内容拷贝一份,这里如注释中所写明的利用三次系统调用实现。
1 | // |
这里duppage()的实现就是按照注释中的内容进行,首先判断原本的页面是不是writable或者COW的,如果是的话那么就将其perm设置成写时复制的。之后现在子进程的地址空间中进行映射,再在父进程的地址空间中进行映射。
1 | // |
fork()函数可以参照dumbfork的主体部分,由于只要赋值UTOP以下的地址空间,而Exception Stack是另外进行分配的,所以采用COW的复制方式到USTACKTOP就为止了。
1 | // |
kern/trapentry.S和kern/trap.c当中由于我是用的是lab3里面challenge所描述的循环写法,这里并不需要做修改。
在kern/env.c的env_alloc()函数中设定EFLAG
1 | // Enable interrupts while in user mode. |
在sched_halt()当中所需要注意的就是取消掉sti的注释,设置IF位使得空闲CPU并不会屏蔽中断。
1 | asm volatile ( |
只需要在trap_dispatch()当中添加分发的分支即可,这里需要按照注释内容在进行sched_yield()之前调用lapic_eoi()来确认中断。
1 | // Handle clock interrupts. Don't forget to acknowledge the |
sys_ipc_recv()当中主要做的操作就是首先进行参数的检查,检查完了之后将其填入env当中,并且让出CPU等待发送消息的进程将其重新设置为RUNNABLE。
1 | // Block until a value is ready. Record that you want to receive |
sys_ipc_try_send()的操作主要是对于注释里面所提到的所有可能的错误情形进行检查,当srcva < UTOP的时候,和sys_page_map()当中的处理非常相似。在最终修改接收方env里面对应的值,并且将返回值设置成0。
1 | // Try to send 'value' to the target env 'envid'. |
在lib/ipc.c当中要提供用户态可用的进行send和recv操作的接口。两个函数的相同之处在于如果没有传递地址映射的话,那么要讲地址设置成一个UTOP上方的值。
这里ipc_recv()只要根据返回值r进行两种情况的区分即可:
1 | // Receive a value via IPC and return it. |
而对于ipc_send()则是通过一个循环来不断地尝试发送信息,为了防止一直占用CPU,每次循环中都会调用sys_yield()主动让出。
1 | // Send 'val' (and 'pg' with 'perm', if 'pg' is nonnull) to 'toenv'. |
实现完了之后lab4的基础内容就已经结束了,执行make grade可以得到如下的输出:
1 | spin: OK (1.8s) |
看到三部分都可以拿到全部分数。
这一个challenge所要完成的是一个共享除了栈之外所有的地址空间的fork操作,记为sfork()。
首先实现了一个sduppage()函数,所做的是将父进程的地址映射给复制到子进程上,对于权限并不做修改,可以看做只是在sys_page_map()的基础上的封装。
1 | static int |
之后就是sfork()函数的实现,代码如下:
1 | int |
可以看到与之前所实现的fork()函数的主体相对比,区别只存在16-26行。这里从栈底往下来进行duppage的操作,当超过栈顶之后,in_stack会被设置成false,之后就是共享的地址空间,全部调用sduppage()。
到这里都是没有什么问题的,重点在于如何将thisenv这个全局变量能够使得不同的进程都能够得到其自身对应的Env结构体,否则的话,在sfork()的过程中,子进程会修改thisenv的指针。导致无论在父进程还是子进程当中,thisenv指向的都是子进程!
最为简单的想法就是通过sys_getenvid()系统调用得到envid,之后查找对应的Env结构体,由于两个进程共享地址空间,所以利用全局变量是不太方便的,一个简单方法是利用宏进行实现。
考虑第一种解决方案:
1 |
这种写法可以完成需求,但是他是一个地址,而在libmain()当中以及fork()当中都有对于thisenv进行初始化的操作,这样需要进行额外的代码修改。
第二种解决方案:
1 | extern const volatile struct Env *realenv; |
利用逗号进行分隔,首先进行一个赋值操作,然后提供一个可以作为运算左值的对象,问题在于thisenv会被用作是cprintf()当中的参数,而逗号分隔会使得参数数量改变。
第三种解决方案:
1 | extern const volatile struct Env *realenv; |
由于C中的逗号表达式以及赋值表达式所返回的都是值而不是对象,所以用先取地址再解引用的方式可以获得一个能作为运算左值的对象。这种方式理论上是没有问题的,但是由于当中会进行赋值操作,所以编译器会认为可能会导致结果出现偏差,会报warning。编译方式将warning视作error,所以这行不通。
最终采用的解决方案为利用一个新的指针数组存下所有Env结构体的地址,然后采用类似第一种解决方案的操作,不过得到的是一个可以作为赋值左值的对象。在inc/lib.c当中,添加关于penvs指针数组的声明,以及将thisenv作为一个宏进行声明。
1 | extern const volatile struct Env *penvs[NENV]; |
在lib/libmain.c当中声明penvs数组,并将其初始化。
1 | const volatile struct Env * penvs[NENV]; |
在这样的操作下thisenv就可以完美兼容所有代码当中的情况了,不需要修改其他任何的实现。
执行pingpongs.c可以得到如下的输出:
1 | enabled interrupts: 1 2 |
可以发现实际上两个进程确实是共享了地址空间,并且thisenv能够正确的指向进程自身了。
如果将其中的sfork()修改成fork()的话,得到的输出如下:
1 | enabled interrupts: 1 2 |
不同进程中的val值是不会共享的,综上测试可以说明sfork()的实现没有问题。
Denis came to Nastya and discovered that she was not happy to see him… There is only one chance that she can become happy. Denis wants to buy all things that Nastya likes so she will certainly agree to talk to him.
The map of the city where they live has a lot of squares, some of which are connected by roads. There is exactly one way between each pair of squares which does not visit any vertex twice. It turns out that the graph of the city is a tree.
Denis is located at vertex 1 at the time 0. He wants to visit every vertex at least once and get back as soon as possible.
Denis can walk one road in 1 time. Unfortunately, the city is so large that it will take a very long time to visit all squares. Therefore, Denis took a desperate step. He pulled out his pocket time machine, which he constructed in his basement. With its help, Denis can change the time to any non-negative time, which is less than the current time.
But the time machine has one feature. If the hero finds himself in the same place and at the same time twice, there will be an explosion of universal proportions and Nastya will stay unhappy. Therefore, Denis asks you to find him a route using a time machine that he will get around all squares and will return to the first and at the same time the maximum time in which he visited any square will be minimal.
Formally, Denis’s route can be represented as a sequence of pairs:, where is number of square, and is time in which the boy is now.
The following conditions must be met:
You need to find a route such that the maximum time in any square will be minimal, that is, the route for which will be the minimum possible.
Input
The first line contains a single integer — the number of squares in the city.
The next n−1 lines contain two integers and - the numbers of the squares connected by the road.
It is guaranteed that the given graph is a tree.
Output
In the first line output the integer — the length of the path of Denis.
In the next lines output pairs — pairs that describe Denis’s route (as in the statement).
All route requirements described in the statements must be met.
It is guaranteed that under given restrictions there is at least one route and an answer whose length does not exceed . If there are several possible answers, print any.
Example
input
1 | 5 |
output
1 | 13 |
一个树形的结构,每次可以往相邻节点移动,需要花费一单位时间,或者是修改时间为任意非负值,但是不能够两次在同一时间到达同一节点(的组合必须是惟一的)。问从根节点出发,最后回到根节点所需要的最大时间的最小的时候的遍历方法。如果有多个方法只需要输出任何一种。
可以知道一个事情,遍历整棵树的最大时间,至少为当中所有节点的最大度数:
考虑到任何节点,需要通过该节点次来遍历所有邻居然后还需要再通过一次就才能够返回该节点的祖先。那么只要能够构造一种遍历的方法,使得可以满足最大时间为,即满足了题意。考虑对任何一个子树,到达子树的根节点父节点的时候为,子树一共有个子节点:
情况1: ,在中途不需要进行时间回溯
………
情况2:需要进行时间回溯
…
在代码中backt就是返回父节点的时间,idx为当前的节点下标,t为当前时间节点,fa记录的是父节点的下标。整体进行一遍dfs遍历,按照上述的逻辑进行时间的修改。
1 |
|