先回顾一下全贝叶斯推断:
训练阶段:
p(θ∣Xtr,Ytr)=∫p(Ytr∣Xtr,θ)p(θ)dθp(Ytr∣Xtr,θ)p(θ)
测试阶段:
p(y∣x,Xtr,Ytr)=∫p(y∣x,θ)p(θ∣Xtr,Ytr)dθ
红色分布难以计算,使得后验分布只有在面对简单的共轭模型才能被精确求解
Approximate inference
概率模型:p(x,θ)=p(x∣θ)p(θ)
变分推断(Variational Inference):
采用一个简单的分布来近似后验:p(θ∣x)≈q(θ)∈Q
蒙特卡洛方法(MCMC):
从没有标准化的p(θ∣x)里面进行采样(因为下面归一化的部分难以计算):
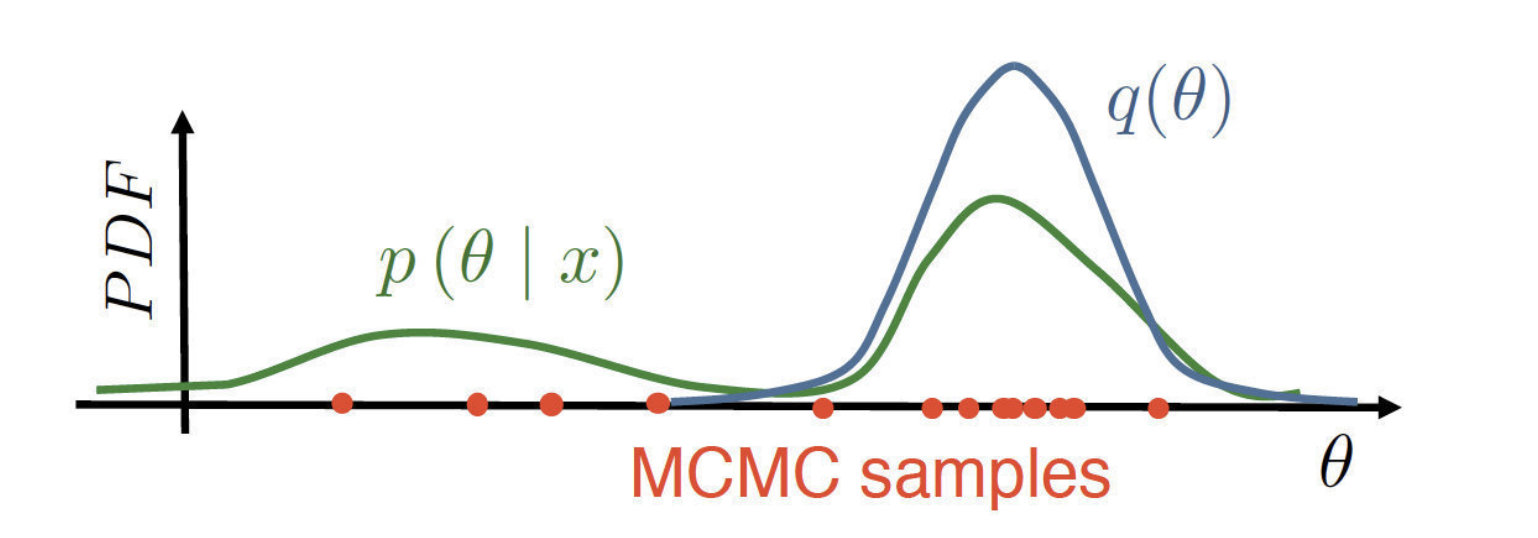
Variational inference
logp(x)=∫q(θ)logp(x)dθ=∫q(θ)logp(θ∣x)p(x,θ)dθ=∫q(θ)logp(θ∣x)q(θ)p(x,θ)q(θ)dθ=∫q(θ)logq(θ)p(x,θ)dθ+∫q(θ)logp(θ∣x)q(θ)dθ=L(q(θ))+KL(q(θ)∣∣p(θ∣x))
前面的绿色部分是ELBO(Evidence lower bound)
后面的红色部分是用于变分推断的KL散度,KL散度越小,说明我们的估计与后验分布越接近
但是后验分布是未知的,否则就不需要求解了,再看一遍上面这个公式:
logp(x)=L(q(θ))+KL(q(θ)∣∣p(θ∣x))
可以发现前面logp(x)与q(θ)是没有关系的,那么要最小化KL散度,实际上就相当于最大化ELBO:
KL(q(θ)∣∣p(θ∣x))→q(θ)∈Qmin⇔L(q(θ))→q(θ)∈Qmax
改写一遍变分下界:
L(q(θ))=∫q(θ)logq(θ)p(x,θ)dθ=∫q(θ)logq(θ)p(x∣θ)p(θ)dθ=Eq(θ)logp(x∣θ)−KL(q(θ)∣∣p(θ))
前面绿色的为数据项,后面红色的为正则项
最终的优化问题就在于:
L(q(θ))=∫q(θ)logq(θ)p(x,θ)dθ→q(θ)∈Qmax
问题的关键是,怎么对于一个概率分布进行最优化
Mean Field Variational Inference
Mean Field Approximation
L(q(θ))=∫q(θ)logq(θ)p(x,θ)dθ→q(θ)=q1(θ1)⋅…⋅qm(θm)max
块坐标上升法(Block coordinate assent):
每次都固定除了一个维度分布其他的部分{qi(θi)}i≠j,然后对一个维度上的分布进行优化
L(q(θ))→qj(θj)max
由于除了qj(θj)其他维度都是固定的,可以得到如下的数学推导:
L(q(θ))=∫q(θ)logq(θ)p(x,θ)=Eq(θ)logp(x,θ)−Eq(θ)logq(θ)=Eq(θ)logp(x,θ)−k=1∑mEqk(θk)logqk(θk)=Eqj(θj)[Eqi≠jlogp(x,θ)]−Eqj(θj)logqj(θj)+Const{rj(θj)=Zj1exp(Eqi≠jlogp(x,θ))}=Eqj(θj)logqj(θj)rj(θj)+Const=−KL(qj(θj)∣∣rj(θj))+Const
在块坐标下降中的每一步优化问题转化为了:
L(q(θ))=−KL(qj(θj)∣∣rj(θj))+Const→qj(θj)max
实际上就是要最小化KL散度,容易发现解为:
qj(θj)=rj(θj)=Zj1exp(Eqi≠jlogp(x,θ))
Parametric variational inference
考虑对于变分分布的参数族:
q(θ)=q(θ∣λ)
限制在于,我们选择了一族固定的分布形式:
- 如果选择的形式过于简单,我们可能不能有效地建模数据
- 如果选择的形式足够复杂,我们不能保证把它训得很好来拟合数据
但这样就把变分推断就转变成了一个参数优化问题:
L(q(θ∣λ))=∫q(θ∣λ)logq(θ∣λ)p(x,θ)dθ→λmax
只要我们能够计算变分下界(ELBO)对于θ的导数,那么就可以使用数值优化方法来对这个优化问题进行求解
Summary
| Full Bayesian inference |
p(θ∣x) |
| MP inference |
p(θ∣x)≈δ(θ−θMP) |
| Mean field variational inference |
p(θ∣x)≈q(θ)=∏j=1mqj(θj) |
| Parametric variational inference |
p(θ∣x)≈q(θ)=q(θ∣λ) |