Conditional=MarginalJoint,p(x∣y)=p(y)p(x,y)
Product Rule
联合分布可以被表示为一维的条件分布的乘积
p(x,y,z)=p(x∣y,z)p(y∣z)p(z)
Sum Rule
任何边缘分布可以利用联合分布通过积分得到
p(y)=∫p(x,y)dx
Bayes理论
p(y∣x)=p(x)p(x,y)=p(x)p(x∣y)p(y)=∫p(x∣y)p(y)dyp(x∣y)p(y)
Bayes理论定义了当新的信息到来的时候,可能性的改变:
Posterior=EvidenceLikelihood×Prior
统计推断(Statistical inference)
问题描述:
给定从分布p(x∣θ)中得到的独立同分布变量X=(x1,…,xn),来估计θ
常规方法:
采用极大似然估计(maximum likelihood estimation)
θML=argmaxp(X∣θ)=argmaxi=1∏np(xi∣θ)=argmaxi=1∑n=logp(xi∣θ)
贝叶斯方法:
用先验p(θ)来编码θ的不确定性,然后采用贝叶斯推断
p(θ∣X)=∫∏i=1np(xi∣θ)p(θ)dθ∏i=1np(xi∣θ)p(θ)
频率学派vs. 贝叶斯学派
|
频率学派 |
贝叶斯学派 |
| 变量 |
有随机变量也有确定的 |
全都是随机变量 |
| 适用范围 |
n>>d |
∀n |
-
现代机器学习模型中可训练的参数数量已经接近训练数据的大小了
-
频率学派得到的结果实际上是一种受限制的Bayesian方法:
n/d→∞limp(θ∣x1,…,xn)=δ(θ−θML)
注:此处的δ函数指的是狄拉克函数
贝叶斯方法的优点
- 可以用先验分布来编码我们的先验知识或者是希望的做种结果
- 先验是一种正则化的方式
- 相对于θ的点估计方法,后验还包含有关于估计的不确定性关系的信息
概率机器学习模型
数据:
- x – 观察到变量的集合(features)
- y – 隐变量的集合(class label / hidden representation, etc.)
模型:
- θ – 模型的参数(weights)
Discriminative probabilistic ML model

通常假设θ的先验与x没有关系
p(y,θ∣x)=p(y∣x,θ)p(θ)
Examples:
- 分类或者回归任务(隐层表示比观测空间简单得多)
- 机器翻译(隐层表示和观测的空间有着相同的复杂度)
Generative probabilistic ML model

可能会很难训练,因为通常而言观测到的x会比隐层复杂很多。
Examples:
贝叶斯机器学习模型的训练与预测
Training阶段:θ上的贝叶斯推断
p(θ∣Xtr,Ytr)=∫p(Ytr∣Xtr,θ)p(θ)dθp(Ytr∣Xtr,θ)p(θ)
结果:采用p(θ)分布比仅仅采用一个θML有着更好地效果
- 模型融合总是比一个最优模型的效果更好
- 后验分布里面含有所有从训练数据中学到的相关内容,并且可以模型提取用于计算新的后验分布
Testing阶段:
- 从training中我们得到了后验分布p(θ∣Xtr,Ytr)
- 获得了新的的数据点x
- 需要计算对于y的预测
p(y∣x,Xtr,Ytr)=∫p(y∣x,θ)p(θ∣Xtr,Ytr)dθ
重新看一遍
训练阶段:
p(θ∣Xtr,Ytr)=∫p(Ytr∣Xtr,θ)p(θ)dθp(Ytr∣Xtr,θ)p(θ)
测试阶段:
p(y∣x,Xtr,Ytr)=∫p(y∣x,θ)p(θ∣Xtr,Ytr)dθ
红色部分的内容通常是难以计算的!
共轭分布
我们说分布p(y)和p(x∣y)是共轭的当且仅当p(y∣x)和p(y)是同类的,即后验分布和先验分布同类。
p(y)∈A(α),p(x∣y)∈B(β)⇒p(y∣x)∈A(α′)
Intuition:
p(y∣x)=∫p(x∣y)p(y)dyp(x∣y)p(y)∝p(x∣y)p(y)
- 由于任何A中的分布是归一化的,分母是可计算的
- 我们需要做的就是计算α′
这种情况下贝叶斯推断可以得到闭式解!
常见的共轭分布如下表:
| Likelihood p(x∣y) |
y |
Conjugate prior p(y) |
| Gaussian |
μ |
Gaussian |
| Gaussian |
σ−2 |
Gamma |
| Gaussian |
(μ,σ−2) |
Gaussian-Gamma |
| Multivariate Gaussian |
Σ−1 |
Wishart |
| Bernoulli |
p |
Beta |
| Multinomial |
(p1,…,pm) |
Dirichlet |
| Poisson |
λ |
Gamma |
| Uniform |
θ |
Pareto |
举个例子:丢硬币
- 我们有一枚可能是不知道是否均匀的硬币
- 任务是预测正面朝上的概率θ
- 数据:X=(x1,…,xn),x∈{0,1}
概率模型如下:
p(x,θ)=p(x∣θ)p(θ)
其中对于p(x∣θ)的似然为:
Bern(x∣θ)=θx(1−θ)1−x
但是不知道p(θ)的先验是多少
怎样选择先验概率分布?
- 正确的定义域:θ∈[0,1]
- 包含先验知识:一枚硬币是均匀的可能性非常大
- 推断复杂度的考虑:使用共轭先验
Beta分布是满足所有条件的!
Beta(θ∣a,b)=B(a,b)1θa−1(1−θ)b−1
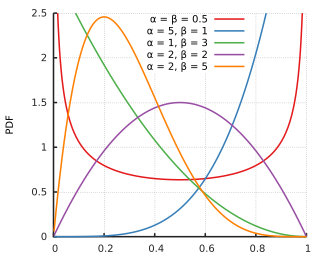
同样也适用于大部分不均匀硬币的情况
让我们来检验似然和先验是不是共轭分布:
p(x∣θ)=θx(1−θ)1−xp(θ)=B(a,b)1θa−1(1−θ)b−1
方法——检验先验和后验是不是在同样的参数族里面
p(θ)p(θ∣x)=Cθα(1−θ)β=C′p(x∣θ)p(θ)=C′θx(1−θ)1−xB(a,b)1θa−1(1−θ)b−1=B(a,b)C′θx+a−1(1−θ)b−x=C′′θα′(1−θ)β′
由于先验和后验形式相同,所以确实是共轭的!
现在考虑接收到数据之后的贝叶斯推断:
p(θ∣X)=Z1p(X∣θ)p(θ)=Z1p(θ)i=1∏np(xi∣θ)=Z1B(a,b)1θa−1(1−θ)b−1i=1∏nθxi(1−θ)1−xi=Z′1θa+∑i=1nxi−1(1−θ)b+n−∑i=1n−1=Z′1θa′−1(1−θ)b′−1
新的参数为:
a′=a+i=1∑nxib′=b+n−i=1∑nxi
那么问题来了,当没有共轭分布的时候我们应该怎么做?
最简单的方法:选择可能性最高的参数
训练阶段:
θMP=argmaxp(θ∣Xtr,Ytr)=argmaxp(Ytr∣Xtr,θ)p(θ)
测试阶段:
p(y∣x,Xtr,Ytr)=∫p(y∣x,θ)p(θ,Xtr,Ytr)dθ≈p(y∣x,θMP)
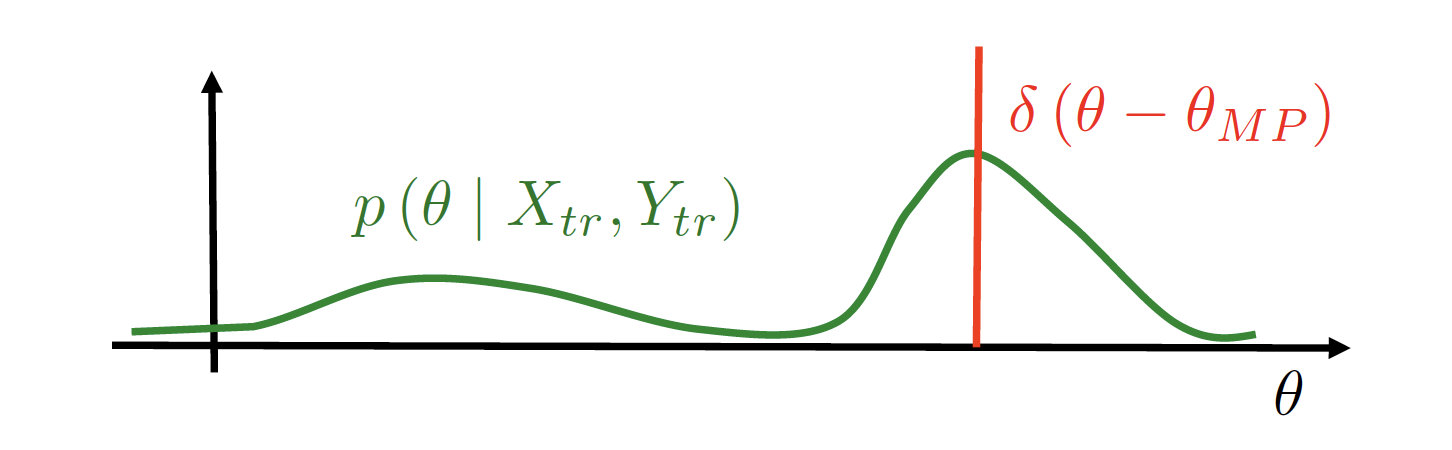
这种情况下我们并不能计算出正确的后验。