基本介绍
传统处理数据集中缺失值一般有两种方法:
- 直接针对缺失值进行建模
- 对于缺失值进行填充得到完整数据集,再用常规方法进行分析
- 删除法,会丢失到一些重要信息,缺失率越高,情况越严重
- 用均值/中位数/众数填充,没有利用现有的其他信息
- 基于机器学习的填充方法
- EM
- KNN
- Matrix Factorization
考虑一个这样的数据,时间序列X是T=(t0,…,tn−1)的一个观测,X=(xt0,…,xti,…,xtn−1)⊤∈Rn×d,例如:
X=⎣⎡1796 none none none 7 none 9 none 79⎦⎤,T=⎣⎡0513⎦⎤
利用mask矩阵M∈Rn×d来表示X中的值存在与否,如果存在,Mtij=1否则的话Mtij=0。
总体的基本框架如下,generator从随机的输入中生成时间序列数据,discriminator尝试判别是真的数据还是生成的假数据,通过bp进行优化:
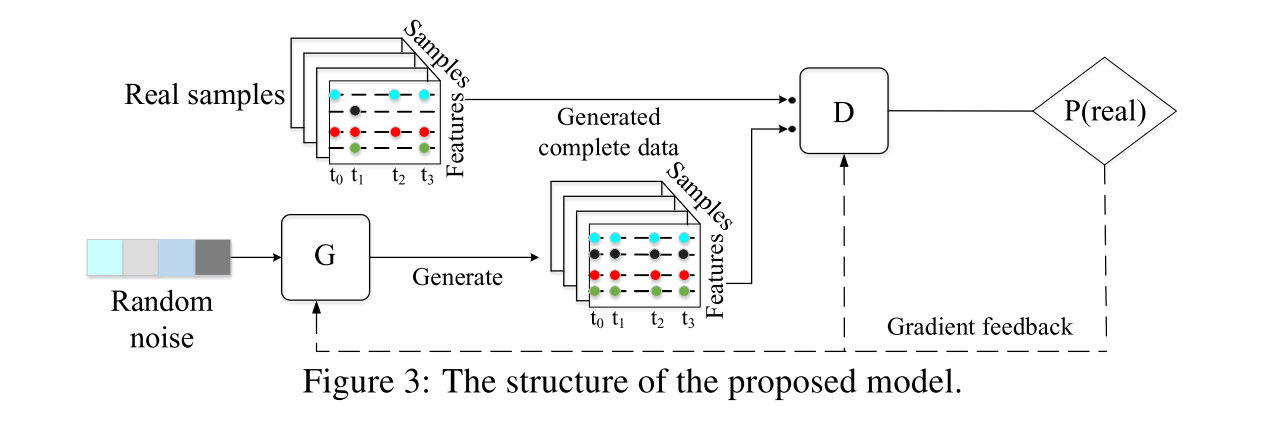
GAN框架
由于最初始的GAN容易导致模型坍塌的问题,采用WGAN(利用Wasserstein距离),他的loss如下:
LG=Ez∼Pg[−D(G(z))]LD=Ez∼Pg[D(G(z))]−Ex∼Pr[D(x)]
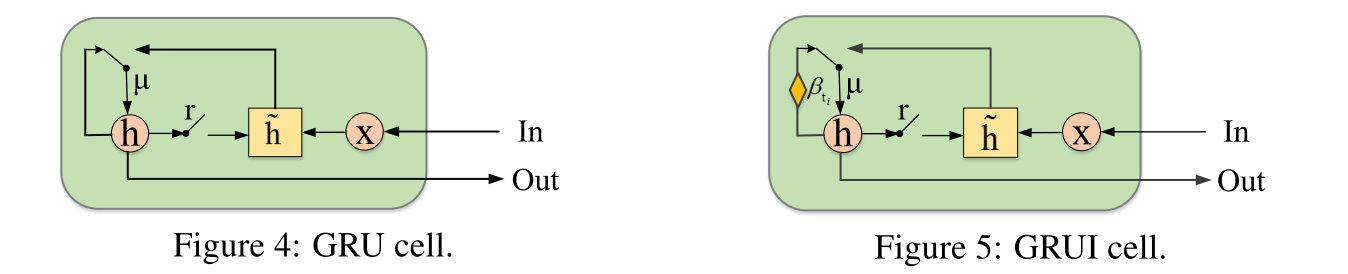
采用基于GRU的GRUI单元作为G和D的基本网络,来缓解时间间隔不同所带来的的问题。可以知道的是,老的观测值所带来的影响随着时间的推移应当更弱,因为他的观测值已经有了一段时间的缺失。
时间衰减(time decay)
采用一个time lag矩阵δ∈Rn×d来表示当前值和上一个有效值之间的时间间隔。
δtij=⎩⎨⎧ti−ti−1,δti−1j+ti−ti−1,0,Mti−1j==1Mti−1j==0&i>0i==0;δ=⎣⎡05805130580513⎦⎤
利用一个时间衰减向量β来控制过去观测值的影响,每一个值都应当是在(0,1]的,并且可以知道的是,δ中的值越大,β中对应的值应当越小,其中Wβ更希望是一个完全的矩阵而不是对角阵。
βti=1/emax(0,Wβδti+bβ)
GRUI
GRUI的更新过程如下:
hti−1′μtirtih~tihti=βti⊙hti−1=σ(Wμ[hti−1′,xti]+bμ)=σ(Wr[hti−1′,xti]+br)=tanh(Wh~[rti⊙hti−1′,xti]+bh~)=(1−μti)⊙hti−1′+μti⊙h~ti
D和G的结构:
D过一个GRUI层,最后一个单元的隐层表示过一个FC(带dropout)
G用一个GRUI层和一个FC,G是自给的网络(self-feed network),当前的输出会作为下一个迭代的输入。最开始的输入是一个随机噪声。假数据的δ的每一行都是常量。
G和D都采用batch normalization。
缺失值填补方法
考虑到x的缺失,可能G(z)在x没有缺失的几个值上面都表现的非常好,但是却可能和实际的x差得很多。
文章中定义了一个两部分组成的loss function来衡量填补的好坏。第一部分叫做masked reconstruction loss,用来衡量和原始不完整的时间序列数据之间的距离远近。第二部分是discriminative loss,让生成的G(z)尽可能真实。
Masked Reconstruction Loss
只考虑没有缺失值之间的平方误差
Lr(z)=∥X⊙M−G(z)⊙M∥2
Discriminative Loss
Ld(z)=−D(G(z))
Imputation Loss
Limputation(z)=Lr(z)+λLd(z)
对于每个原始的时间序列x,从高斯分布中采样z,通过一个已经训练好的G获得G(z)。之后通过最小化Limputation(z)来进行训练,收敛之后用G(z)填充缺失的部分。
ximputed=M⊙x+(1−M)⊙G(z)