这一章采用神经网络方法来搭建模型,从而能够解决更为实际的问题。
神经网络单元
一个神经单元可以看做,一个线性的变换再加上一个非线性的激活函数,常见的激活函数如下:
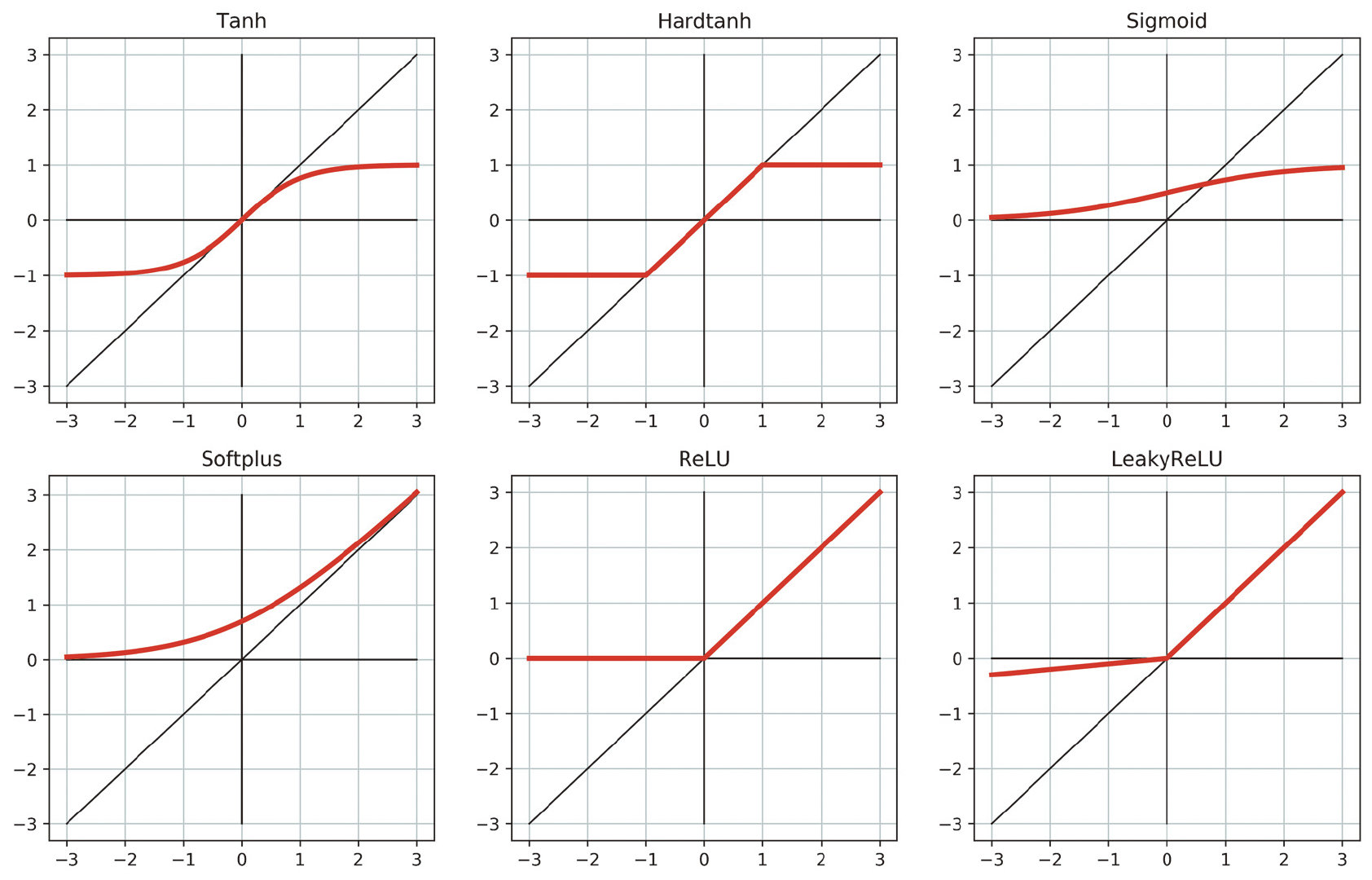
其中ReLU是最为通用的激活函数!
激活函数的通用特征:
- 非线性
- 可导(可以存在点不连续,比如Hardtanh和ReLU)
- 有至少一个敏感的域,输入的变化会改变输出的变化
- 有至少一个不敏感的域,输入的变化对输出的变化无影响或极其有限
- 当输入是负无穷的时候有lower bound,当输入是正无穷的时候有upper bound(非必须)
PyTorch中的nn
PyTorch中有一系列构建好的module来帮助构造神经网络,一个module是nn.Module基类派生出来的一个子类。每个Module有一个或多个Parameter对象。一个Module同样可以可以由一个或多个submodules,并且可以同样可以追踪他们的参数。
注意:submodules不能再list或者dict里面。否则的话优化器没有办法定位他们,更新参数。如果要使用submodules的list或者dict,PyTorch提供了nn.ModuleList和nn.ModuleDict。
直接调用nn.Module实际上等同调用了forward方法,理论上调用forward也可以达到同样的效果,但是实际上不应该这么操作。
现在的training loop长这个样子:
1 | def training_loop(n_epochs, optimizer, model, loss_fn, t_u_train, t_u_val, t_c_train, t_c_val): |
调用方法:
1 | linear_model = nn.Linear(1,1) |
现在考虑一个稍微复杂一点的情况,一个线性模型套一个激活函数再套一个线性模型,PyTorch提供了nn.Sequential容器:
1 | seq_model = nn.Sequential(nn.Linear(1,13), |
可以通过model.parameters()来得到里面的参数:
1 | [param.shape for param in seq_model.parameters()] |
如果一个模型通过很多子模型构成的话,能够通过名字辨别是非常方便的事情,PyTorch提供了named_parameters方法
1 | for name, param in seq_model.named_parameters(): |
Sequential按模块在里面出现的顺序进行排序,从0开始命名。Sequential同样接受OrderedDict,可以在里面对传入Sequential的每个model进行命名
1 | from collections import OrderedDict |
同样可以把子模块当做属性来对于特定的参数进行访问:
1 | seq_model.output_linear.bias |
可以定义nn.Module的子类来更大程度上的自定义:
1 | class SubclassModel(nn.Module): |
这样极大提高了自定义能力,可以在forward里面做任何你想做的事情,甚至可以写类似于activated_t = self.hidden_activation(hidden_t) if random.random() >0.5 else hidden_t,由于PyTorch采用的是动态的运算图,所以无论random.random()返回的是什么都可以正常运行。
在subclass内部所定义的module会自动的注册,和named_parameters中类似。nn.ModuleList和nn.ModuleDict也会自动进行注册。
PyTorch中有functional,它代表输出完全由输入决定,像nn.Tanh这种可以直接写在forward里面。
1 | class SubclassFunctionalModel(nn.Module): |
在PyTorch1.0中有许多函数被放到了torch命名空间中,更多的函数留在torch.nn.functional里面。