简介
首先要解决的就是为什么需要空间金字塔池化(SPP)这个问题,它到底为了什么而出现。
对于以往的神经网络结构大部分所需要的都是固定的网络大小输入,但是现实中很多图片数据并不是固定大小的输入。以往的方法往往是通过裁剪(Crop)和扭曲(Warp),但是前者会导致信息的丢失,后者可能会导致图片的失真,都会使得数据分布发生一定变化。
SPP解决的就是图片大小不同的问题,使得输入可以是任意宽和高的图片。
Spatial Pyramid Pooling Layer
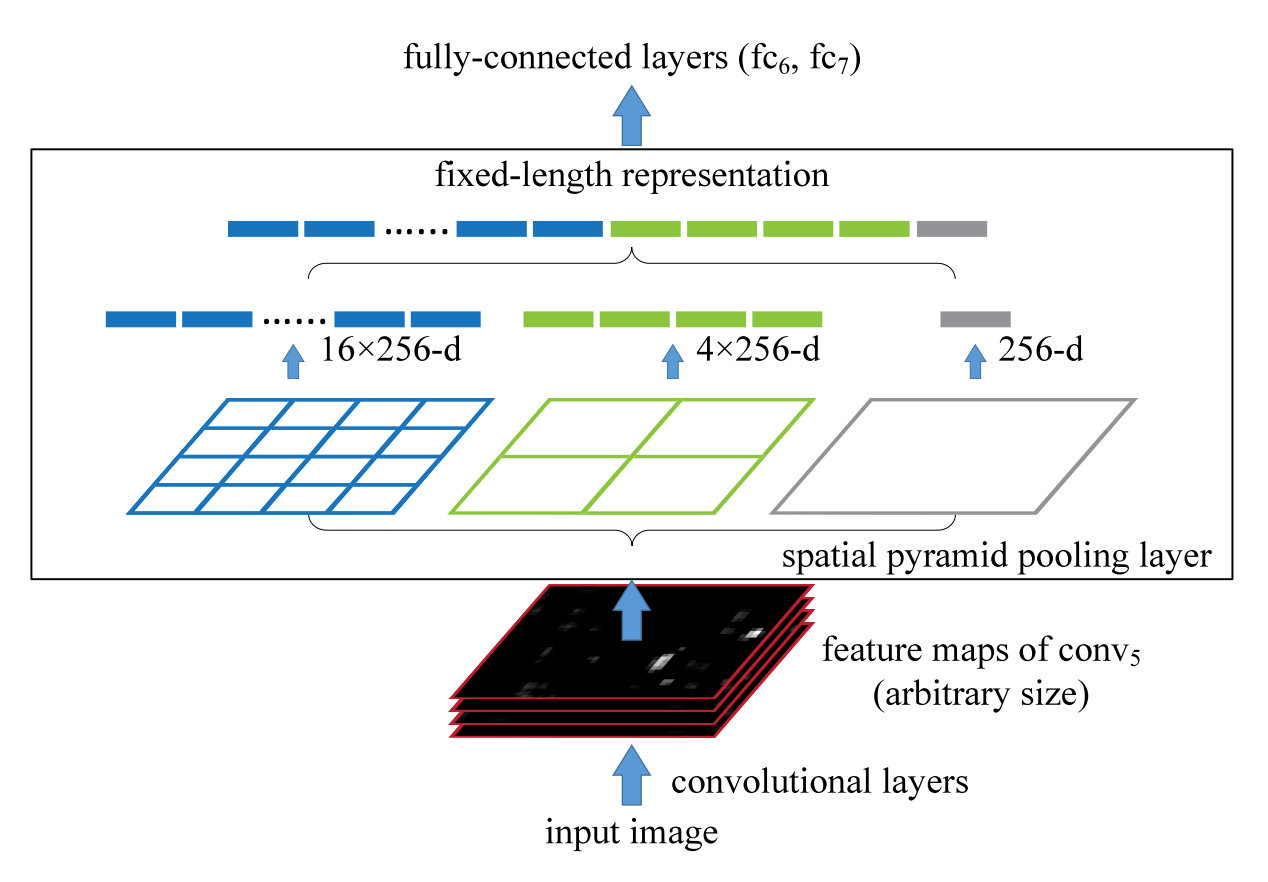
如上图所示的SPP-Net 中有若干个并行的池化层,将卷积层的结果 池化成 的一层层结果,再将其所有结果进行拼接之后与 FC 层相连。
由于只有最后的FC层对于输入的大小是存在硬性要求的,当输入为任意大小的图片时,我们可以随意进行卷积、池化。在过FC 层之前,通过 SPP 层,将图片抽象出固定大小的特征(即多尺度特征下的固定特征向量抽取)。
好处有以下几点:
- SPP可以针对于不同的input size输出固定长度的向量,这是原本的滑动窗口池化做不到的
- SPP用了多层级的空间信息,而滑动窗口池化操作使用的窗口大小是单一的
- 由于输入的大小是可以变化的,所以SPP可以提取到不同尺度上信息
Training
- Single-size Training
单输入size大小的训练方法同普通的训练相同,这里所需要的就是设置好对应的pooling层的stride和window size,以便于之后的SPP层可以输出正确的结果。事实上,这里为了探究single-size的训练主要是为了来测试金字塔池化的行为是否符合预期。
- Multi-size Training
为了防止切换数据带来的overhead过高,这里假设有两种size的输入图片,每一种size训练一个epoch之后切换到另一种。事实上发现采用多尺度的图片,收敛速率和单尺度图片是相似的,并没有带来收敛速率上的损失。
以上两种方法都是只针对训练阶段的,在测试阶段,可以直接将任何尺寸的图片输入到SPP-net当中。
代码实现
基于PyTorch框架的实现如下,在github上看了几个实现大多数都是通过论文当中提供的公式来进行实现的,少部分发现了公式在面对一些不太友好数据的情况会出现输出维度不同的问题,增加了padding的计算方法。
本着不重复造轮子的原则,在我使用的PyTorch-1.5.0当中提供了AdaptiveMaxPool2d和AdaptiveAvgPool2d方法,直接采用其进行构造,代码逻辑会更为清晰和行数也会更短。
同时提供一个outputdim的辅助函数,通过输入的之前卷积层结果的channel数来计算输出维度。
1 | import torch |
测试如下:
1 | spp = SpatialPyramidPooling() |
输出结果为:
1 | torch.Size([8, 448]) |
的确将不同大小的输入给调整成了统一大小。