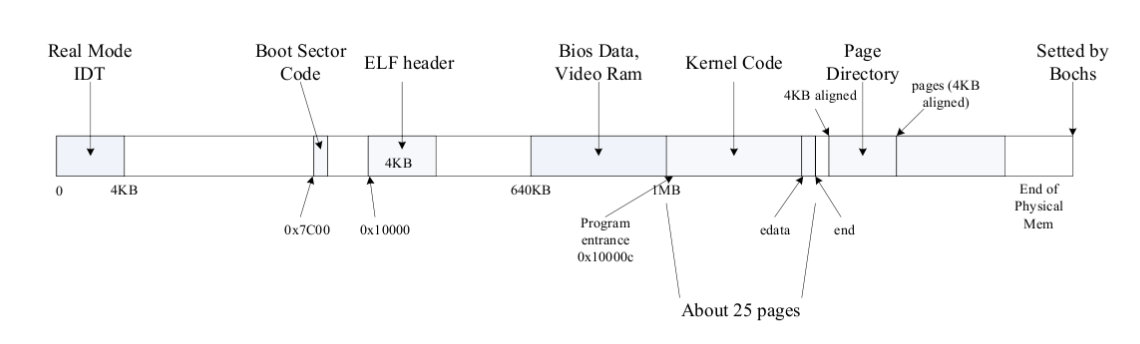
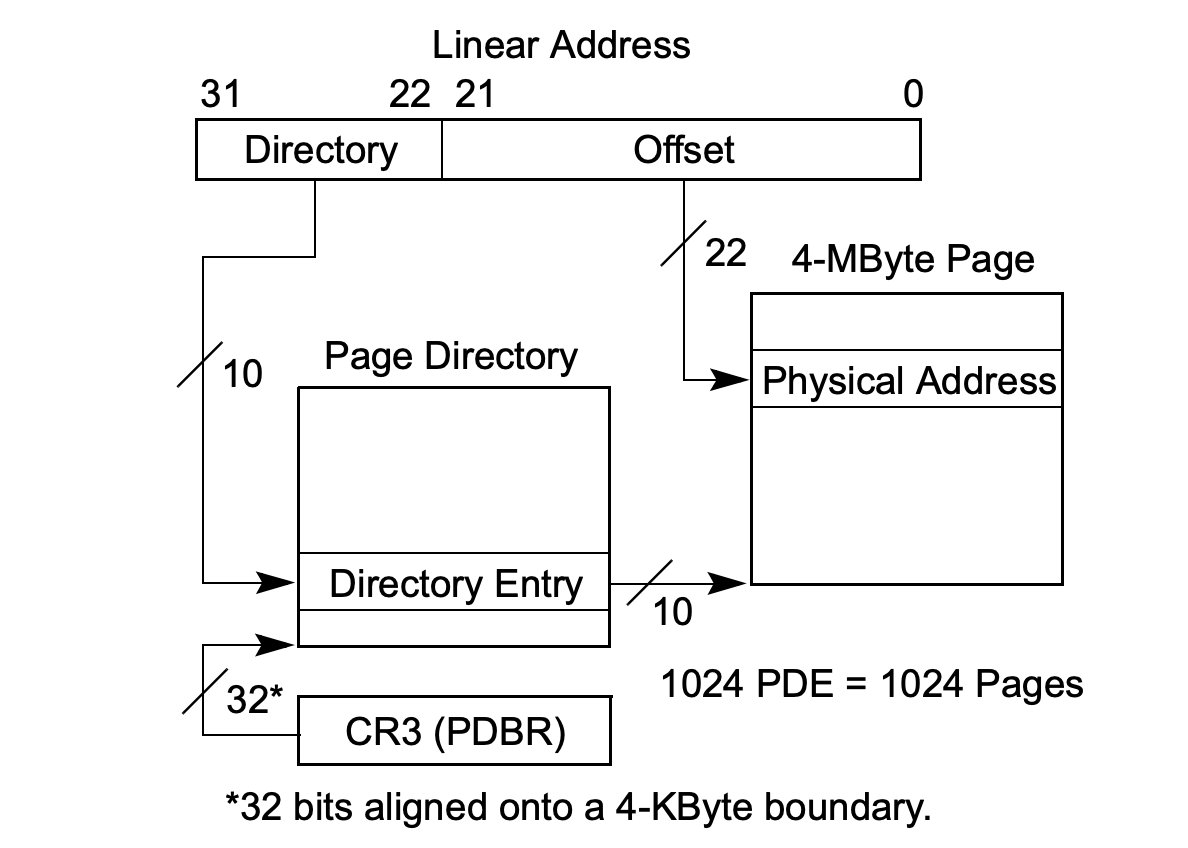
// A linear address 'la' has a three-part structure as follows: // // +--------10------+-------10-------+---------12----------+ // | Page Directory | Page Table | Offset within Page | // | Index | Index | | // +----------------+----------------+---------------------+ // \--- PDX(la) --/ \--- PTX(la) --/ \---- PGOFF(la) ----/ // \---------- PGNUM(la) ----------/
在inc/memlayout.h中可以看到PageInfo的结构如下:
1 2 3 4 5 6 7 8 9 10 11 12
structPageInfo { // Next page on the free list. structPageInfo *pp_link;
// pp_ref is the count of pointers (usually in page table entries) // to this page, for pages allocated using page_alloc. // Pages allocated at boot time using pmap.c's // boot_alloc do not have valid reference count fields.
// This simple physical memory allocator is used only while JOS is setting // up its virtual memory system. page_alloc() is the real allocator. // // If n>0, allocates enough pages of contiguous physical memory to hold 'n' // bytes. Doesn't initialize the memory. Returns a kernel virtual address. // // If n==0, returns the address of the next free page without allocating // anything. // // If we're out of memory, boot_alloc should panic. // This function may ONLY be used during initialization, // before the page_free_list list has been set up. staticvoid * boot_alloc(uint32_t n) { staticchar *nextfree; // virtual address of next byte of free memory char *result;
// Initialize nextfree if this is the first time. // 'end' is a magic symbol automatically generated by the linker, // which points to the end of the kernel's bss segment: // the first virtual address that the linker did *not* assign // to any kernel code or global variables. if (!nextfree) { externchar end[]; nextfree = ROUNDUP((char *) end, PGSIZE); }
// Allocate a chunk large enough to hold 'n' bytes, then update // nextfree. Make sure nextfree is kept aligned // to a multiple of PGSIZE. // // LAB 2: Your code here. if(npages * PGSIZE < (uint32_t)(nextfree + n - KERNBASE)) // out of memory panic("boot_alloc: We are out of memory.\n"); result = nextfree; nextfree = ROUNDUP(nextfree + n, PGSIZE);
由于在注释中要求要对于对于out of memory的情况需要触发panic,所以这里在34行进行了一个分配内容是否超过物理内存限制的检查。如果一切正常的话就进行分配,采用已经定义好的ROUNDUP宏来进行页面对齐。
如果n为0的时候,37行代码不会产生任何改变,符合注释中所描述的代码逻辑。
mem_init
1 2 3 4 5 6 7 8 9
// Allocate an array of npages 'struct PageInfo's and store it in 'pages'. // The kernel uses this array to keep track of physical pages: for // each physical page, there is a corresponding struct PageInfo in this // array. 'npages' is the number of physical pages in memory. Use memset // to initialize all fields of each struct PageInfo to 0. // Your code goes here:
// At IOPHYSMEM (640K) there is a 384K hole for I/O. From the kernel, // IOPHYSMEM can be addressed at KERNBASE + IOPHYSMEM. The hole ends // at physical address EXTPHYSMEM. #define IOPHYSMEM 0x0A0000 #define EXTPHYSMEM 0x100000
/* This macro takes a physical address and returns the corresponding kernel * virtual address. It panics if you pass an invalid physical address. */ #define KADDR(pa) _kaddr(__FILE__, __LINE__, pa)
staticinlinevoid* _kaddr(constchar *file, int line, physaddr_t pa) { if (PGNUM(pa) >= npages) _panic(file, line, "KADDR called with invalid pa %08lx", pa); return (void *)(pa + KERNBASE); }
// // Initialize page structure and memory free list. // After this is done, NEVER use boot_alloc again. ONLY use the page // allocator functions below to allocate and deallocate physical // memory via the page_free_list. // void page_init(void) { // The example code here marks all physical pages as free. // However this is not truly the case. What memory is free? // 1) Mark physical page 0 as in use. // This way we preserve the real-mode IDT and BIOS structures // in case we ever need them. (Currently we don't, but...) // 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE) // is free. // 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must // never be allocated. // 4) Then extended memory [EXTPHYSMEM, ...). // Some of it is in use, some is free. Where is the kernel // in physical memory? Which pages are already in use for // page tables and other data structures? // // Change the code to reflect this. // NB: DO NOT actually touch the physical memory corresponding to // free pages! size_t i; uint32_t pa_free_start = (uint32_t)((char *)boot_alloc(0) - KERNBASE); // case 1: pages[0].pp_ref = 1; pages[0].pp_link = NULL; // case 2, 3, 4: for (i = 1; i < npages; i++) { if(IOPHYSMEM <= i * PGSIZE && i * PGSIZE < pa_free_start) { pages[i].pp_ref = 1; pages[i].pp_link = NULL; } else { pages[i].pp_ref = 0; pages[i].pp_link = page_free_list; page_free_list = &pages[i]; } } }
// // Allocates a physical page. If (alloc_flags & ALLOC_ZERO), fills the entire // returned physical page with '\0' bytes. Does NOT increment the reference // count of the page - the caller must do these if necessary (either explicitly // or via page_insert). // // Be sure to set the pp_link field of the allocated page to NULL so // page_free can check for double-free bugs. // // Returns NULL if out of free memory. // // Hint: use page2kva and memset struct PageInfo * page_alloc(int alloc_flags) { // Fill this function in structPageInfo* alloc_page = page_free_list; if(alloc_page == NULL) returnNULL; page_free_list = alloc_page->pp_link; alloc_page->pp_link = NULL; if(alloc_flags && ALLOC_ZERO) memset(page2kva(alloc_page), 0, PGSIZE); return alloc_page; }
// // Return a page to the free list. // (This function should only be called when pp->pp_ref reaches 0.) // void page_free(struct PageInfo *pp) { // Fill this function in // Hint: You may want to panic if pp->pp_ref is nonzero or // pp->pp_link is not NULL. if(pp->pp_ref != 0 || pp->pp_link != NULL) panic("page_free: pp_ref or pp_link is not zero!\n"); pp->pp_link = page_free_list; page_free_list = pp; return; }
// Given 'pgdir', a pointer to a page directory, pgdir_walk returns // a pointer to the page table entry (PTE) for linear address 'va'. // This requires walking the two-level page table structure. // // The relevant page table page might not exist yet. // If this is true, and create == false, then pgdir_walk returns NULL. // Otherwise, pgdir_walk allocates a new page table page with page_alloc. // - If the allocation fails, pgdir_walk returns NULL. // - Otherwise, the new page's reference count is incremented, // the page is cleared, // and pgdir_walk returns a pointer into the new page table page. // // Hint 1: you can turn a PageInfo * into the physical address of the // page it refers to with page2pa() from kern/pmap.h. // // Hint 2: the x86 MMU checks permission bits in both the page directory // and the page table, so it's safe to leave permissions in the page // directory more permissive than strictly necessary. // // Hint 3: look at inc/mmu.h for useful macros that manipulate page // table and page directory entries. // pte_t * pgdir_walk(pde_t *pgdir, constvoid *va, int create) { // Fill this function in uint32_t pdx = PDX(va); uint32_t ptx = PTX(va); if(pgdir[pdx] == 0) { if(create) { structPageInfo* newpte = page_alloc(1); if(newpte == NULL) returnNULL; ++(newpte->pp_ref); pgdir[pdx] = page2pa(newpte) | PTE_P | PTE_W | PTE_U; } else returnNULL; } physaddr_t pte = PTE_ADDR(pgdir[pdx]) | (ptx << 2); return KADDR(pte); }
// // Map [va, va+size) of virtual address space to physical [pa, pa+size) // in the page table rooted at pgdir. Size is a multiple of PGSIZE, and // va and pa are both page-aligned. // Use permission bits perm|PTE_P for the entries. // // This function is only intended to set up the ``static'' mappings // above UTOP. As such, it should *not* change the pp_ref field on the // mapped pages. // // Hint: the TA solution uses pgdir_walk staticvoid boot_map_region(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm) { // Fill this function in while(size > 0) { pte_t* pte = pgdir_walk(pgdir, (void *)va, 1); if(pte == NULL) panic("boot_map_region: Fail to alloc new page, run out of memory!\n"); *pte = pa | perm | PTE_P; size -= PGSIZE; va += PGSIZE, pa += PGSIZE; } }
// // Return the page mapped at virtual address 'va'. // If pte_store is not zero, then we store in it the address // of the pte for this page. This is used by page_remove and // can be used to verify page permissions for syscall arguments, // but should not be used by most callers. // // Return NULL if there is no page mapped at va. // // Hint: the TA solution uses pgdir_walk and pa2page. // struct PageInfo * page_lookup(pde_t *pgdir, void *va, pte_t **pte_store) { // Fill this function in pte_t* pte = pgdir_walk(pgdir, va, 0); if(pte == NULL) returnNULL; physaddr_t pa = PTE_ADDR(*pte); if(pte_store) *pte_store = pte; return pa2page(pa); }
// // Unmaps the physical page at virtual address 'va'. // If there is no physical page at that address, silently does nothing. // // Details: // - The ref count on the physical page should decrement. // - The physical page should be freed if the refcount reaches 0. // - The pg table entry corresponding to 'va' should be set to 0. // (if such a PTE exists) // - The TLB must be invalidated if you remove an entry from // the page table. // // Hint: The TA solution is implemented using page_lookup, // tlb_invalidate, and page_decref. // void page_remove(pde_t *pgdir, void *va) { // Fill this function in pte_t* pte_store; structPageInfo* pp = page_lookup(pgdir, va, &pte_store); if(pp == NULL) return; *pte_store = 0; page_decref(pp); tlb_invalidate(pgdir, va); }
// // Map the physical page 'pp' at virtual address 'va'. // The permissions (the low 12 bits) of the page table entry // should be set to 'perm|PTE_P'. // // Requirements // - If there is already a page mapped at 'va', it should be page_remove()d. // - If necessary, on demand, a page table should be allocated and inserted // into 'pgdir'. // - pp->pp_ref should be incremented if the insertion succeeds. // - The TLB must be invalidated if a page was formerly present at 'va'. // // Corner-case hint: Make sure to consider what happens when the same // pp is re-inserted at the same virtual address in the same pgdir. // However, try not to distinguish this case in your code, as this // frequently leads to subtle bugs; there's an elegant way to handle // everything in one code path. // // RETURNS: // 0 on success // -E_NO_MEM, if page table couldn't be allocated // // Hint: The TA solution is implemented using pgdir_walk, page_remove, // and page2pa. // int page_insert(pde_t *pgdir, struct PageInfo *pp, void *va, int perm) { // Fill this function in pte_t* pte = pgdir_walk(pgdir, va, 1); if(pte == NULL) return -E_NO_MEM; physaddr_t pa = page2pa(pp); ++(pp->pp_ref); if(*pte) page_remove(pgdir, va); *pte = pa | perm | PTE_P; return0; }
// Map 'pages' read-only by the user at linear address UPAGES // Permissions: // - the new image at UPAGES -- kernel R, user R // (ie. perm = PTE_U | PTE_P) // - pages itself -- kernel RW, user NONE // Your code goes here: n = ROUNDUP(npages*sizeof(struct PageInfo), PGSIZE); for (i = 0; i < n; i += PGSIZE) page_insert(kern_pgdir, pa2page(PADDR(pages) + i), (void *)(UPAGES + i), PTE_U | PTE_P);
// Use the physical memory that 'bootstack' refers to as the kernel // stack. The kernel stack grows down from virtual address KSTACKTOP. // We consider the entire range from [KSTACKTOP-PTSIZE, KSTACKTOP) // to be the kernel stack, but break this into two pieces: // * [KSTACKTOP-KSTKSIZE, KSTACKTOP) -- backed by physical memory // * [KSTACKTOP-PTSIZE, KSTACKTOP-KSTKSIZE) -- not backed; so if // the kernel overflows its stack, it will fault rather than // overwrite memory. Known as a "guard page". // Permissions: kernel RW, user NONE // Your code goes here: boot_map_region(kern_pgdir, KSTACKTOP - KSTKSIZE, KSTKSIZE, PADDR(bootstack), PTE_W);
// Map all of physical memory at KERNBASE. // Ie. the VA range [KERNBASE, 2^32) should map to // the PA range [0, 2^32 - KERNBASE) // We might not have 2^32 - KERNBASE bytes of physical memory, but // we just set up the mapping anyway. // Permissions: kernel RW, user NONE // Your code goes here: //cprintf("kernbase: %x 2^32-kernbase: %x", KERNBASE, (~KERNBASE)+1); boot_map_region(kern_pgdir, KERNBASE, (~KERNBASE) + 1, 0, PTE_W);
We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel’s memory? What specific mechanisms protect the kernel memory?
Revisit the page table setup in kern/entry.S and kern/entrypgdir.c. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
# We haven't set up virtual memory yet, so we're running from # the physical address the boot loader loaded the kernel at: 1MB # (plus a few bytes). However, the C code is linked to run at # KERNBASE+1MB. Hence, we set up a trivial page directory that # translates virtual addresses [KERNBASE, KERNBASE+4MB) to # physical addresses [0, 4MB). This 4MB region will be # sufficient until we set up our real page table in mem_init # in lab 2.
# Load the physical address of entry_pgdir into cr3. entry_pgdir # is defined in entrypgdir.c. movl $(RELOC(entry_pgdir)), %eax movl %eax, %cr3 # Turn on paging. movl %cr0, %eax orl $(CR0_PE|CR0_PG|CR0_WP), %eax movl %eax, %cr0
# Now paging is enabled, but we're still running at a low EIP # (why is this okay?). Jump up above KERNBASE before entering # C code. mov $relocated, %eax jmp *%eax relocated:
# Clear the frame pointer register(EBP) # so that once we get into debugging C code, # stack backtraces will be terminated properly. movl $0x0,%ebp # nuke frame pointer
staticvoid boot_map_region_normal(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm) { // Fill this function in while(size > 0) { pte_t* pte = pgdir_walk(pgdir, (void *)va, 1); if(pte == NULL) panic("boot_map_region: Fail to alloc new page, run out of memory!\n"); *pte = pa | perm | PTE_P; size -= PGSIZE; va += PGSIZE, pa += PGSIZE; } }
staticvoid boot_map_region_ex(pde_t *pgdir, uintptr_t va, size_t size, physaddr_t pa, int perm) { while(size > 0) { pte_t* pte = pgdir_walk_ex(pgdir, (void *)va, 2); if(pte == NULL) panic("boot_map_region: Fail to alloc new page, run out of memory!\n"); *pte = pa | perm | PTE_P | PTE_PS; size -= PTSIZE; va += PTSIZE, pa+= PTSIZE; } }
check_page_free_list() succeeded! check_page_alloc() succeeded! check_page() succeeded! check_kern_pgdir() succeeded! check_page_installed_pgdir() succeeded! Welcome to the JOS kernel monitor! Type 'help' for a list of commands. K>
题面中所说的"power-of-two allocation unit sizes from 4KB up to some reasonable maximum of your choice."应该就是伙伴系统了。感觉要完全实现除去修改自己写的函数之外需要修改check_page_free_list()以及kern/pmap.h当中的宏以及辅助函数,不知道会不会引发什么其他地方未知的错误,没有进行代码实现。