Gumbel-Softmax Distribution
考虑z是一个定类型的变量,对于每个类型有着概率π1,π2,…,πk。考虑到从这个概率分布中的采样可以用一个onehot向量来表示,当数据量很大的时候满足:
Ep[z]=[π1,…,πk]
Gumbel-Max trick 提供了一个简单且高效的来对符合π这样概率分布的z进行采样的方法:
z=onehot(argimax[gi+logπi])
其中gi是从Gumbel(0,1)中独立采出的,它可以利用Uniform(0,1)中的采样来计算得到:
ug∼Uniform(0,1)=−log(−log(u)).
之后利用softmax来获得一个连续可导对argmax的估计
yi=∑j=1kexp((log(πj)+gj)/τ)exp((log(πi)+gi)/τ)for i=1,…,k
Gumbel-Softmax分布的概率密度如下表是:
pπ,τ(y1,…,yk)=Γ(k)τk−1(i=1∑kπi/yiτ)−ki=1∏k(πi/yiτ+1)
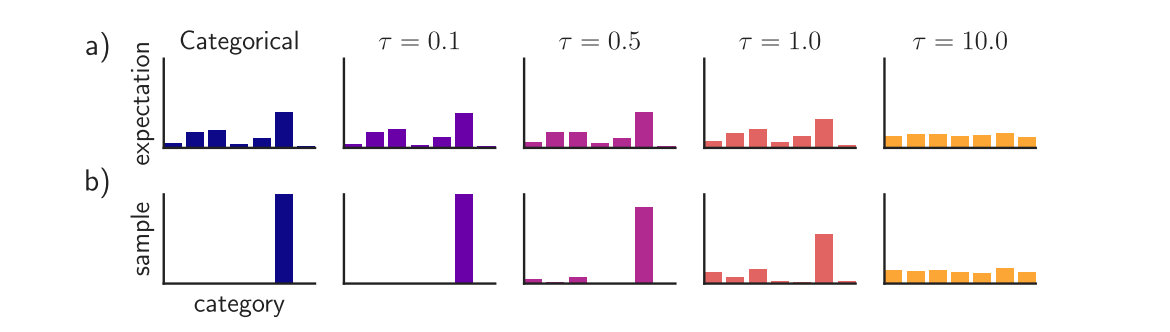
可以知道对于温度τ而言,越接近于零,那么从Gumbel-Softmax分布中的采样就越接近onehot并且Gumbel-Softmax分布同原始的分布p(z)也更加的相似。
Gumbel-Softmax Estimator
可以发现对于任意的τ>0,Gumbel-Softmax分布都是光滑的,可以求出偏导数∂y/∂π对参数π。于是用Gumbel-Softmax采样来代替原有的分类采样,就可以利用反向传播来计算梯度了。
对于学习过程中来说,实际上存在一个tradeoff。当τ较小的时候,得到的sample比较接近onehot但是梯度的方差很大,当τ较大的时候,梯度的方差比较小但是得到的sample更平滑。在实际的操作中,我们通常从一个较高的τ开始,然后逐渐退火到一个很小的τ。事实上,对于很多种的退火方法,结果都表现的不错。
Straight-Through Gumbel-Softmax Estimator
对于有些任务需要严格的将其限制为得到的就是离散的值,那么这个时候可以考虑对于y来做一个arg max得到z,在反向传播的时候利用∇θz≈∇θy来进行梯度的估计。
即通过离散的方式进行采样,但是从连续的路径进行求导。这个叫做ST Gumbel-Softmax estimator,可以知道,当温度τ较高的时候,这依然可以采样得到离散的采样值。
主要总结了一些随机神经网络训练的方法,进行了一个对比。
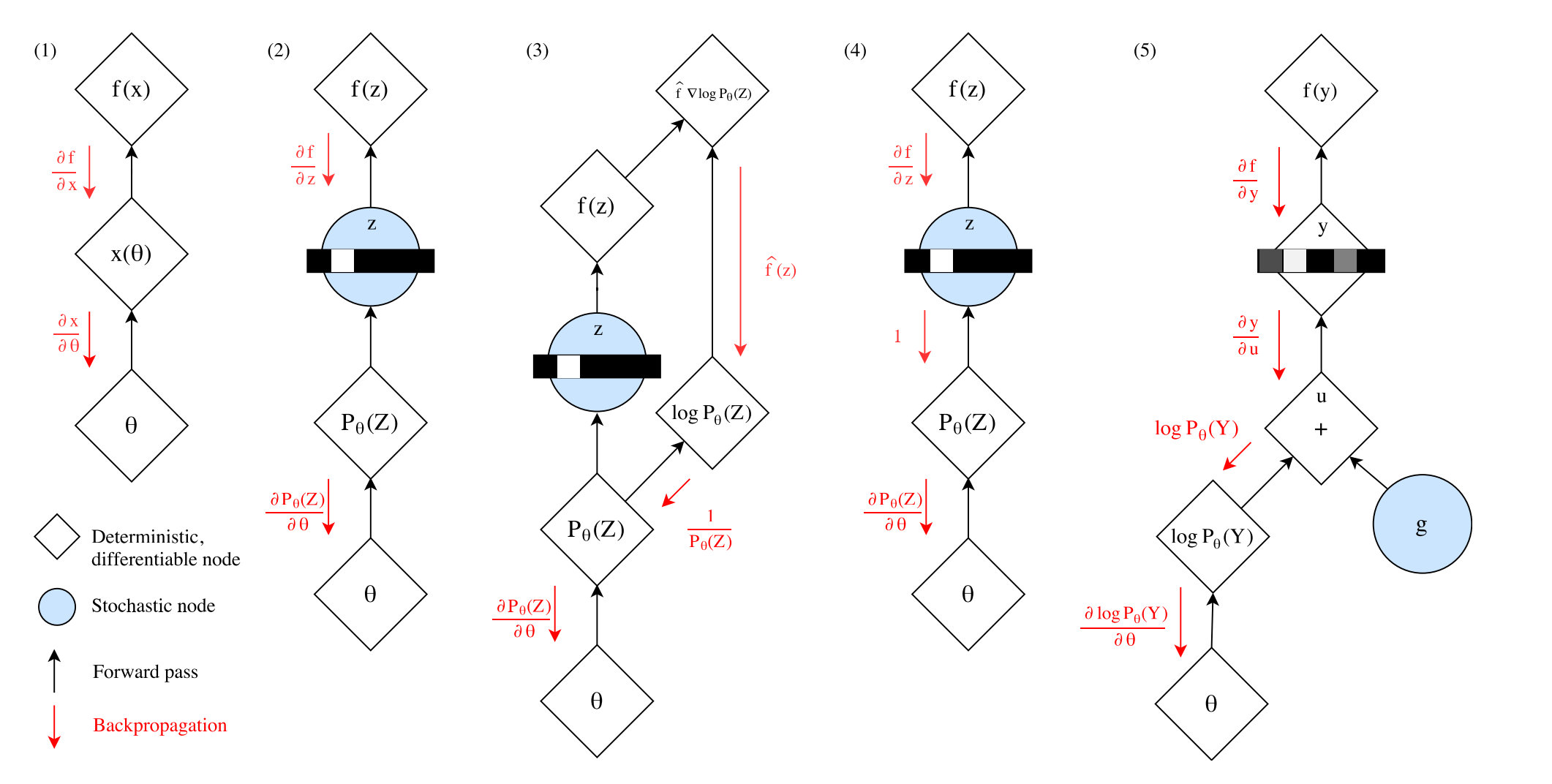
上图中
- 正常的无随机节点的梯度下降
- 存在随机节点的时候,梯度在这个地方不能很好地进行反传
- 采用log trick绕开随机节点传递梯度
- 估计梯度进行传播,例如前文提到的ST Estimator
- 采用重参数化方法,就是这里的Gumbel-Softmax Estimator
Semi-Supervised Generative Models
对于重参数化和log trick就不再多说,这里看一个半监督生成模型的推断。
考虑到一个半监督网络,从带标签数据(x,y)∼DL和不带标签数据x∼DU中进行学习。
有一个分辨网络(D)qϕ(y∣x),一个推断网络(I)qϕ(z∣x,y),和一个生成网络(G)pθ(x∣y,z),通过最大化生成网络输出的log似然的变分下界来进训练。
对于带标签的数据,y是观测到的结果,所以变分下界如下:
logpθ(x,y)≥L(x,y)=Ez∼qϕ(z∣x,y)[logpθ(x∣y,z)]−KL[qϕ(z∣x,y)∣∣pθ(y)p(z)]
对于无标签数据,重点在于对于离散的分布没有办法进行重参数化,所以这里采用的方法是对于margin out所有类别的y,同样是在qϕ(z∣x,y)上面进行推断,得到的变分下界如下所示(有一说一我推的和论文不一样,但我觉得论文里面的公式写错了):
logpθ(x)≥U(x)=Ez∼qϕ(y,z∣x)[logpθ(x∣y,z)+logpθ(y)+logp(z)−logqϕ(y,z∣x)]=Ez∼qϕ(y,z∣x)[logpθ(x∣y,z)−logpθ(y)p(z)qϕ(z∣x,y)+logqϕ(y,z∣x)qϕ(z∣x,y)]=Ez∼qϕ(y,z∣x)[logpθ(x∣y,z)−logpθ(y)p(z)qϕ(z∣x,y)+logqϕ(y∣x)1]=y∑qϕ(y∣x)Ez∼qϕ(z∣x,y)[logpθ(x∣y,z)−logpθ(y)p(z)qϕ(z∣x,y)+logqϕ(y∣x)1]=y∑qϕ(y∣x)Ez∼qϕ(z∣x,y)[logpθ(x∣y,z)−logpθ(y)p(z)qϕ(z∣x,y)]+y∑qϕ(y∣x)logqϕ(y∣x)1=y∑qϕ(y∣x)L(x,y)+H(qϕ(y∣x))
最终得到的最大化目标为下面这个式子:
J=E(x,y)∼DL[L(x,y)]+Ex∼DU[U(x)]+α⋅E(x,y)∼DL[logqϕ(y∣x)]
容易发现,前两项一个是针对带标签数据的变分下界最大化,一个是针对无标签数据的最大化,最后一项代表分辨网络的对数似然,其中α参数越大,说明越看重分辨网络的能力。是一个在分辨网络和生成网络之间进行tradeoff的参数。
对于这种方法,假设要margin out一共k个类别,那么对每个前向/反向步需要O(D+k(I+G)),但是采用Gumbel-Softmax方法进行重参数化,就可以直接进行反向传播而不需要margin out,时间复杂度降低到了O(D+I+G),在类别很多的情况下可以有效降低训练的时间复杂度!