啥是深度学习
Input Representation -> Intermediate Representation -> Output Representation
神经网络学到的就是怎样把Input Representation转化成Output Representation。
Tensor
PyTorch中的tensor起始就是一个n维数组,可以和NumPy中的ndarray相类比,Tensor支持numpy的无缝衔接。
对比NumPy中的ndarray,tensor可以
- 在GPU上进行高效的运算
- 可以在多机器上进行运算
- 可以在运算图上进行追踪
Tensor基础
Python内置List的不足点
- 浮点数会使用超过32bit的大小来进行储存,数据量打的时候比较低效
- 不能从向量化的运算中得到优化,在内存中并不都是连续分布的
- 对于多维的情况只能写list的list,十分的低效
- python解释器和优化编译过后的代码相比比较低效,用C做底层会快很多
可以类似numpy中的索引方式。
可以利用torch.zeros(3,2)或者torch.ones(3,2)的函数进行初始化。
Tensor存储
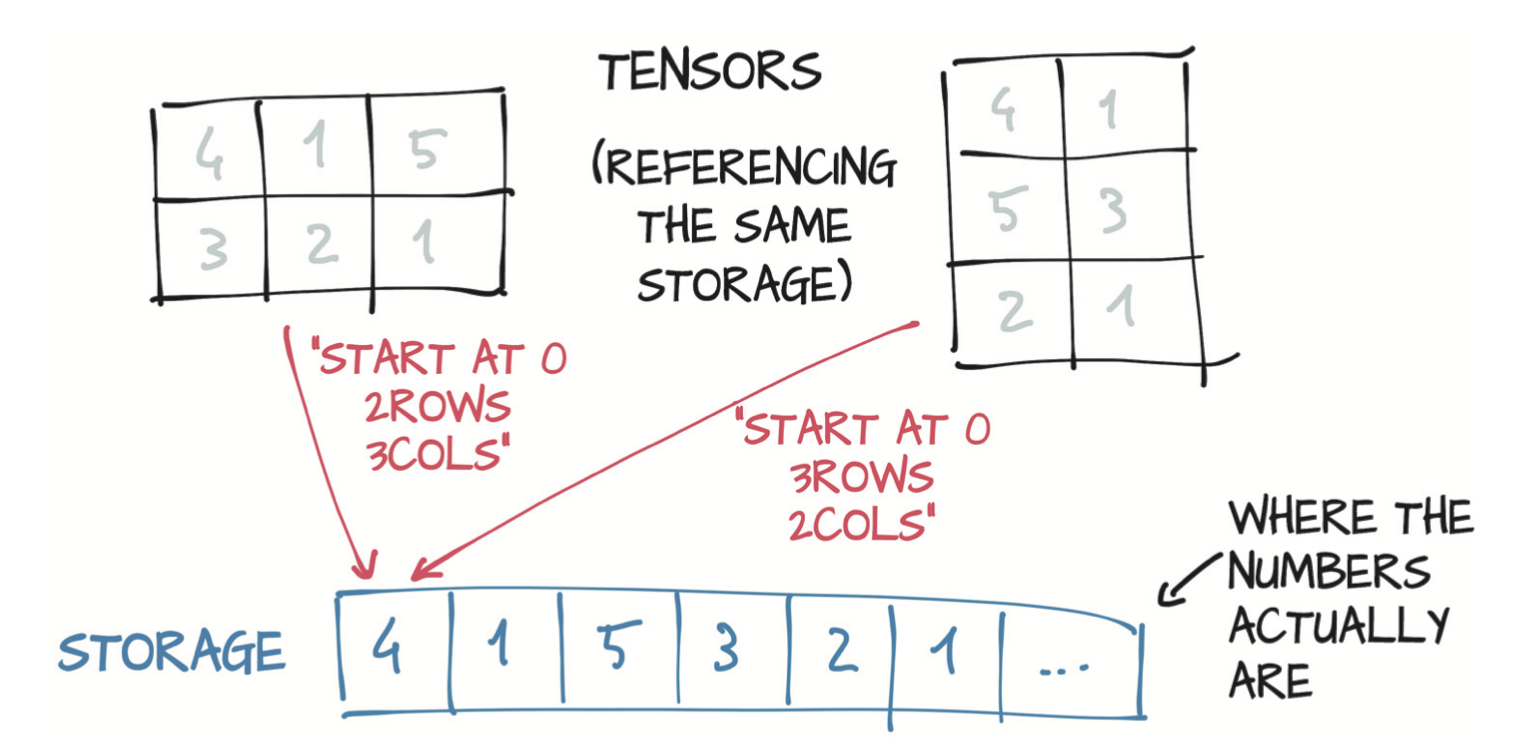
存储形式类似C中数组的方式。
可以利用tensor.storage()方法获得连续的存储,无论本来是几维数组,都可以最终得到一个连续的数组,用正常方法进行索引。类似于得到C中多维数组的首地址。
通过改变storage中的值同样可以改变对应tensor的内容。
Size, storage offset, and strides
-
Size:一个tuple,能告诉这个tensor的每一维有多少元素,
tensor.size()或者tensor.shape -
Storage offset:相对于tensor中第一个元素的offset,
tensor.storage_offset() -
Stride:每一维度上,所需要得到下一个元素的步长,
tensor.stride()
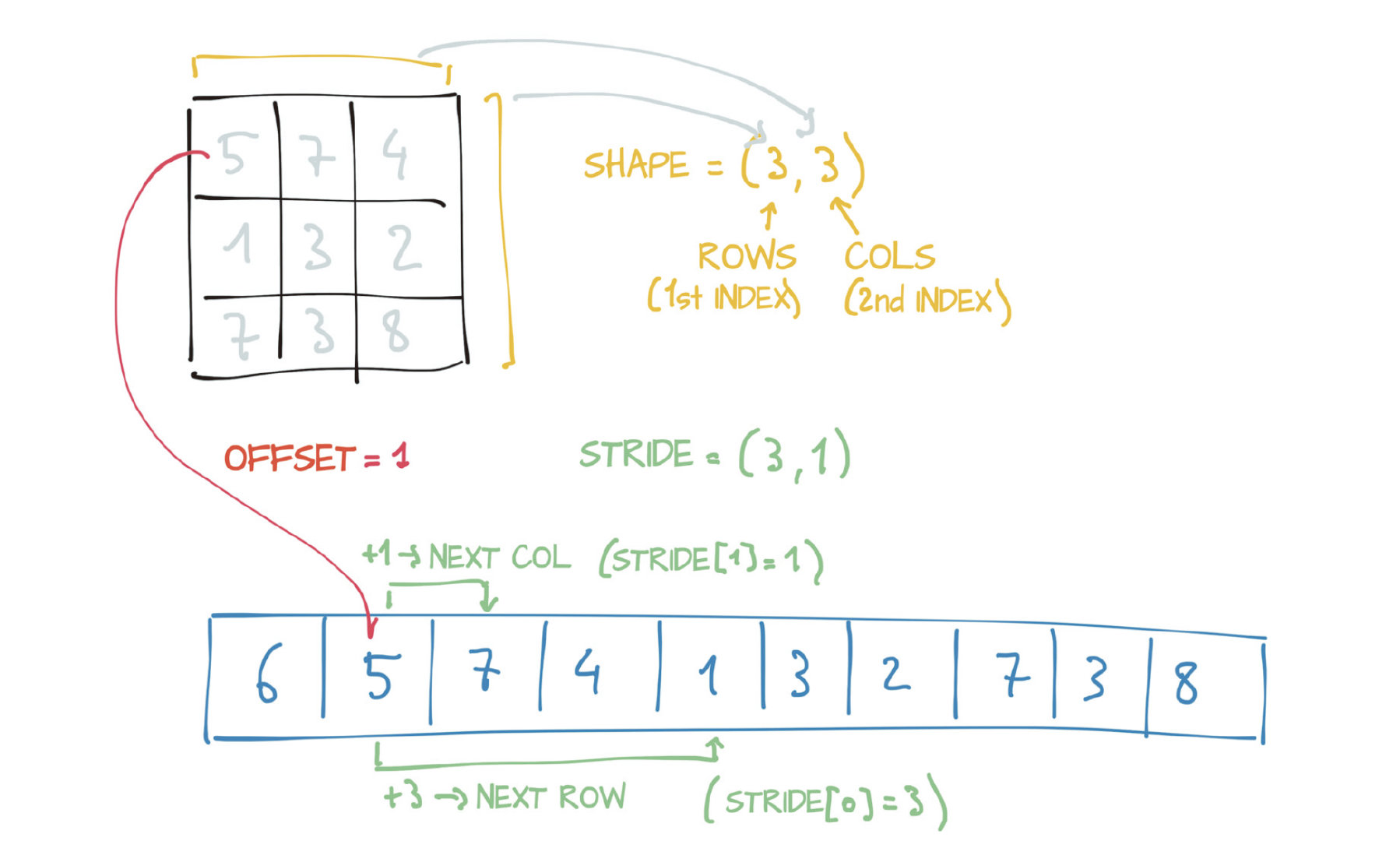
注意:子tensor有着更少的维度,但是实际上有着和原来的tensor都在相同的地方存储,所以对子tensor的改变会改变原来的tensor(直接类比C语言中的多维数组)。可以采用tensor.clone()得到tensor的克隆,这样更改不会改变原来的tensor。
tensor.t()可以将tensor转置,但是他们的存储空间仍然是一样的,只是改变了size和stride。确切的说,只是把对应维度的size和stride进行了交换。
tensor.transpose()可以用来对多维数组的两个维度进行交换,接受两个参数,分别代表dim0和dim1。
contiguous表示tensor在存储中是否按照直接的形式进行存储。可以用tensor.is_contiguous()进行判断,并且可以用tensor.contiguous方法对存储重新排布,不改变size,改变storage和stride。
数值类型
在创建的时候可以用dtype进行指定,默认的是32-bit浮点数,torch.Tensor就是torch.FloatTensor的别名,下面是一些可能的值:
-
torch.float32 or torch.float—32-bit floating-point
-
torch.float64 or torch.double—64-bit, double-precision floating-point
-
torch.float16 or torch.half—16-bit, half-precision floating-point
-
torch.int8—Signed 8-bit integers
-
torch.uint8—Unsigned 8-bit integers
-
torch.int16 or torch.short—Signed 16-bit integers
-
torch.int32 or torch.int—Signed 32-bit integers
-
torch.int64 or torch.long—Signed 64-bit integers
可以通过tensor.dtype来获取类型,可以用对应的方法或者to()进行转换,type()进行同样的操作,但是to()还可以接受额外的参数。
1 | double_points = torch.zeros(10,2).double() |
tensor索引
正常的列表索引,不同维度上切片什么的随你玩
与NumPy的交互
利用tensor.numpy()把tensor转换为numpy中的array。利用tensor.from_numpy()把numpy中的array转换成tensor。
注意一点,如果tensor在CPU上分配的话,是共享存储的,但是如果在GPU上分配的话,会在CPU上重新创造一个array的副本。
Serializing Tensor
tensor的保存与加载,即可以使用路径,也可以使用文件描述符
1 | # Save |
如果要将tensor保存成一个更加可互用的形式,可以采用HDF5格式,一种用于表示多维数组的格式,他内部采用一个字典形式的键值对来进行保存。python通过h5py库支持HDF5格式,它可以接受和返回NumPy array。
1 | import h5py |
在这里’coords’就是key,有趣的一点在于可以只从HDF5中加载一部分的内容,而不用加载全部!
1 | f = h5py.File('../data/p1ch3/ourpoints','r') |
在这种情况下只取出了后面几个点的坐标,返回了一个类似NumPy数组的对象。可以直接采用from_numpy()方法构造tensor。
这种情况下,数据会复制到tensor的storage。
1 | last_points = torch.from_numpy(dset[1:]) |
记得在加载完数据之后关闭文件!
将tensor移动到GPU
在GPU上可以对tensor进行高效的并行计算,tensor有一个device可以用来指定在CPU或者GPU上面,可以在创建时候指定,或者利用to方法创建一个GPU上的副本。
1 | points_gpu = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 4.0]], |
注意!这个时候类型会从torch.FloatTensor变成torch.cuda.FloatTensor,其他的类型类似。
如果有多GPU的情况,可以用一个从零开始的int来指定特定的GPU,如下
1 | points_gpu = points.to(device='cuda:0') |
注意到一个问题,运算结束后,并不会把结果返回到CPU,只是返回一个handle,除非调用了to方法把它弄回了CPU。
可以使用cuda()方法和cpu()方法完成类似上面的事情
1 | points_gpu = points.cuda() #默认是分配到下标为0的GPU |
但是使用to方法可以传递多个参数!比如同时改变device和dtype。
Tensor API
注意有些api会在最后有一个下划线,表示他们是原地修改的,并不会返回一个新的tensor,例如zero_()会原地把矩阵清零。如果没有下划线会返回一个新的tensor,而原tensor保持不变。大致的API分类如下:
-
Creation ops—Functions for constructing a tensor, such as
onesandfrom_numpy -
Indexing, slicing, joining, and mutating ops—Functions for changing the shape,
stride, or content of a tensor, such as transpose
-
Math ops—Functions for manipulating the content of the tensor through computations:
- Pointwise ops—Functions for obtaining a new tensor by applying a function to each element independently, such as
absandcos - Reduction ops—Functions for computing aggregate values by iterating through tensors, such as
mean,std, andnorm - Comparison ops—Functions for evaluating numerical predicates over tensors, such as
equalandmax - Spectral ops—Functions for transforming in and operating in the frequency domain, such as
stftandhamming_window - Other ops—Special functions operating on vectors, such as cross, or matrices, such as
trace - BLAS and LAPACK ops—Functions that follow the BLAS (Basic Linear Algebra Subprograms) specification for scalar, vector-vector, matrix-vector, and matrix-matrix operations
- Pointwise ops—Functions for obtaining a new tensor by applying a function to each element independently, such as
-
Random sampling ops—Functions for generating values by drawing randomly
from probability distributions, such as
randnandnormal -
Serialization ops—Functions for saving and loading tensors, such as
loadand
save
- Parallelism ops—Functions for controlling the number of threads for parallel
CPU execution, such as set_num_threads