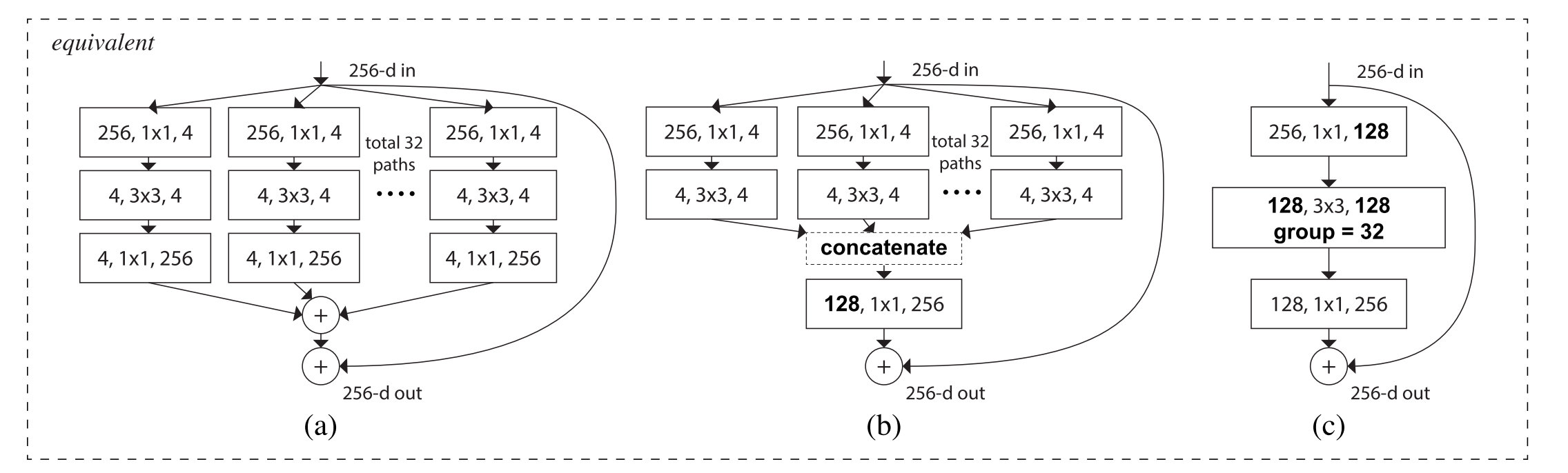
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
| class BasicBlock(nn.Module):
expansion = 0.5
def __init__(self, input_channel, channel, stride):
super(BasicBlock, self).__init__()
output_channel = int(channel * self.expansion)
self.downsample = lambda x: x
if(input_channel != output_channel):
self.downsample = nn.Sequential(
nn.Conv2d(in_channels = input_channel, out_channels = output_channel, kernel_size = 1, stride = stride, bias = False),
nn.BatchNorm2d(output_channel)
)
self.relu = nn.ReLU(inplace = True)
self.convlayers = nn.Sequential(
nn.Conv2d(in_channels = input_channel, out_channels = channel, kernel_size = 3, stride = stride, padding = 1, bias = False),
nn.BatchNorm2d(channel),
nn.ReLU(inplace = True),
nn.Conv2d(in_channels = channel, out_channels = output_channel, kernel_size = 3, stride = 1, padding = 1, bias = False),
nn.BatchNorm2d(output_channel)
)
def forward(self, x):
out = self.downsample(x) + self.convlayers(x)
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 2
def __init__(self, input_channel, channel, stride, expansion = 2, group_num = 32):
super(Bottleneck, self).__init__()
self.expansion = expansion
output_channel = channel * expansion
self.downsample = lambda x: x
if(input_channel != output_channel):
self.downsample = nn.Sequential(
nn.Conv2d(in_channels = input_channel, out_channels = output_channel, kernel_size = 1, stride = stride, bias = False),
nn.BatchNorm2d(output_channel)
)
self.relu = nn.ReLU(inplace = True)
self.convlayers = nn.Sequential(
nn.Conv2d(in_channels = input_channel, out_channels = channel, kernel_size = 1, stride = 1, bias = False),
nn.BatchNorm2d(channel),
nn.ReLU(inplace = True),
nn.Conv2d(in_channels = channel, out_channels = channel, kernel_size = 3, stride = stride, padding = 1, groups = group_num, bias = False),
nn.BatchNorm2d(channel),
nn.ReLU(inplace = True),
nn.Conv2d(in_channels = channel, out_channels = output_channel, kernel_size = 1, stride = 1, bias = False),
nn.BatchNorm2d(output_channel)
)
def forward(self, x):
out = self.downsample(x) + self.convlayers(x)
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, block_nums, input_channel, class_num = 1000):
super(ResNet, self).__init__()
self.stacklayers = nn.Sequential(
nn.Conv2d(in_channels = input_channel, out_channels = 64, kernel_size = 7, stride = 2, padding = 3, bias = False),
nn.BatchNorm2d(64),
nn.ReLU(inplace = True),
nn.MaxPool2d(kernel_size = 3, stride = 2, padding = 1),
self.make_layers(block = block, input_channel = 64, channel = 128, stride = 1, block_num = block_nums[0]),
self.make_layers(block = block, input_channel = int(128 * block.expansion), channel = 256, stride = 2, block_num = block_nums[1]),
self.make_layers(block = block, input_channel = int(256 * block.expansion), channel = 512, stride = 2, block_num = block_nums[2]),
self.make_layers(block = block, input_channel = int(512 * block.expansion), channel = 1024, stride = 2, block_num = block_nums[3]),
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(int(1024*block.expansion), class_num)
)
def make_layers(self, block, input_channel, channel, stride, block_num):
layers = []
layers.append(block(input_channel, channel, stride))
input_channel = int(channel * block.expansion)
for _ in range(1, block_num):
layers.append(block(input_channel, channel, 1))
return nn.Sequential(*layers)
def forward(self, x):
out = self.stacklayers(x)
return out
def ResNeXt_18(input_channel, class_num):
return ResNet(BasicBlock, [2,2,2,2], input_channel, class_num)
def ResNeXt_34(input_channel, class_num):
return ResNet(BasicBlock, [3,4,6,3], input_channel, class_num)
def ResNeXt_50(input_channel, class_num):
return ResNet(Bottleneck, [3,4,6,3], input_channel, class_num)
def ResNeXt_101(input_channel, class_num):
return ResNet(Bottleneck, [3,4,23,3], input_channel, class_num)
def ResNeXt_152(input_channel, class_num):
return ResNet(Bottleneck, [3,8,36,3], input_channel, class_num)
|